
Here’s some thoughts about the Prevent programme, after the half day I spent at the event this week, Youth Empowerment and Addressing Violent Youth Radicalisation in Europe.
It was hosted by the Youth Empowerment and Innovation Project at the University of East London, to mark the launch of the European study on violent youth radicalisation from YEIP.
Firstly, I appreciated the dynamic and interesting youth panel. Young people, themselves involved in youth work, or early researchers on a range of topics. Panelists shared their thoughts on:
- Removal of gang databases and systemic racial targeting
- Questions over online content takedown with the general assumption that “someone’s got to do it.”
- The purposes of Religious Education and lack of religious understanding as cause of prejudice, discrimination, and fear.
From these connections comes trust.
Next, Simon Chambers, from the British Council, UK National Youth Agency, and Erasmus UK, talked about the programme of Erasmus Plus, under the striking sub theme, from these connections comes trust.
- 42% of the world’s population are under 25
- Young people understand that there are wider, underlying complex factors in this area and are disproportionately affected by conflict, economic change and environmental disaster.
- Many young people struggle to access education and decent work.
- Young people everywhere can feel unheard and excluded from decision-making — their experience leads to disaffection and grievance, and sometimes to conflict.
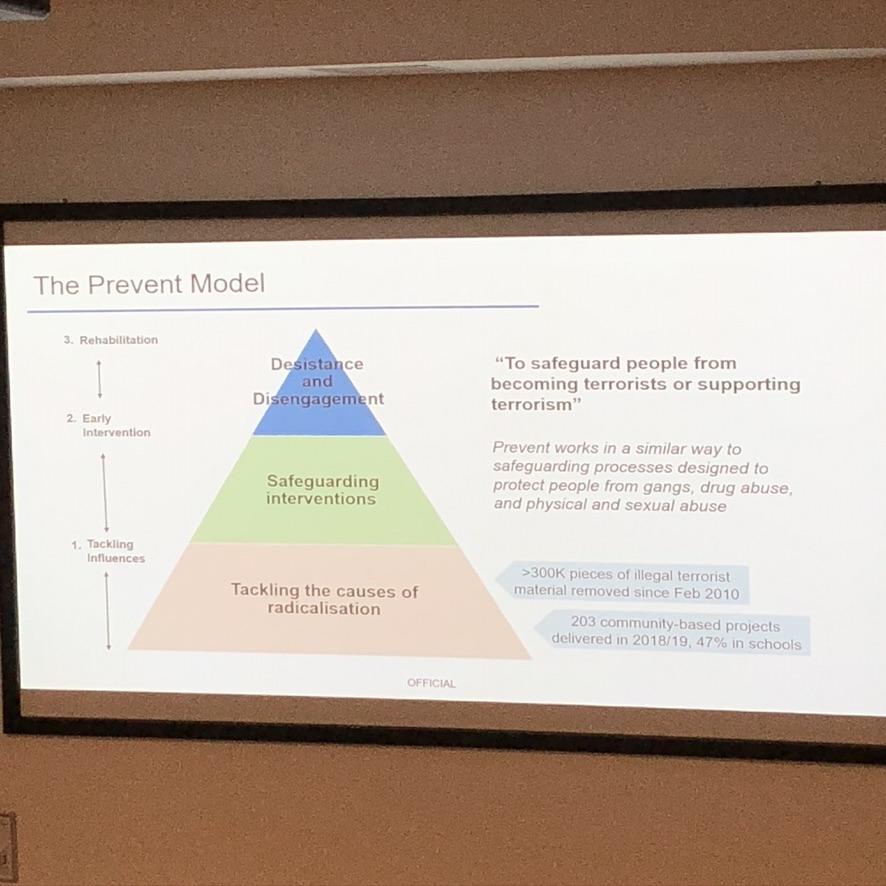
We then heard a senior Home Office presenter speak about Radicalisation: the threat, drivers and Prevent programme.
On Contest 2018 Prevent / Pursue / Protect and Prepare
What was perhaps most surprising was his statement that the programme believes there is no checklist, [but in reality there are checklists] no single profile, or conveyer belt towards radicalisation.
“This shouldn’t be seen as some sort of predictive model,” he said. “It is not accurate to say that somehow we can predict who is going to become a terrorist, because they’ve got poor education levels, or because necessarily have a deprived background.”
But he then went on to again highlight the list of identified vulnerabilities in Thomas Mair‘s life, which suggests that these characteristics are indeed seen as indicators.
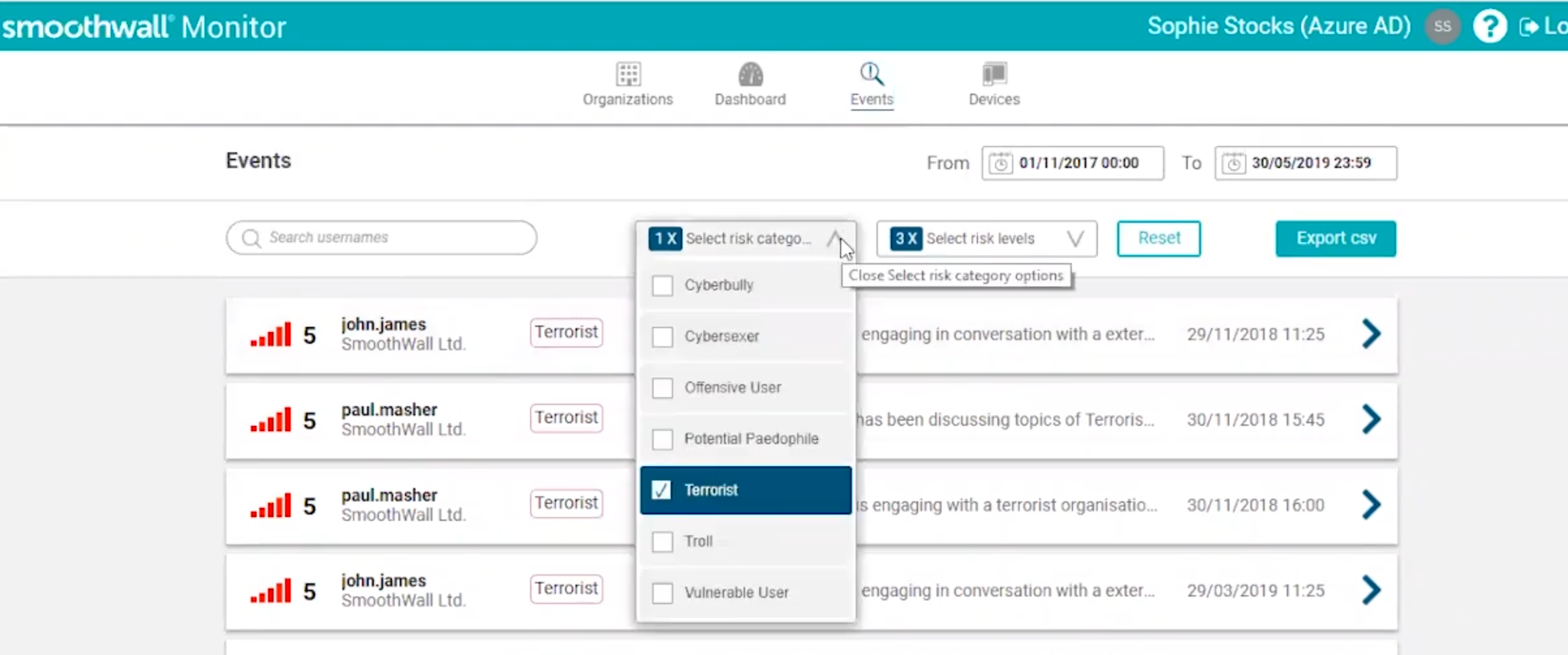
When I look at the ‘safeguarding-in-school’ software that is using vulnerabilities as signals for exactly that kind of prediction of intent, the gap between theory and practice here, is deeply problematic.
One slide included Internet content take downs, and suggested 300K pieces of illegal terrorist material have been removed since February 2010. That number he later suggested are contact with CTIRU, rather than content removal defined as a particular form. (For example it isn’t clear if this is a picture, a page, or whole site). This is still somewhat unclear and there remain important open questions, given its focus in the online harms policy and discussion.
The big gap that was not discussed and that I believe matters, is how much autonomy teachers have, for example, to make a referral. He suggested “some teachers may feel confident” to do what is needed on their own but others, “may need help” and therefore make a referral. Statistics on those decision processes are missing, and it is very likely I believe that over referral is in part as a result of fearing that non-referral, once a computer has tagged issues as Prevent related, would be seen as negligent, or not meeting the statutory Prevent duty as it applies to schools.
On the Prevent Review, he suggested that the current timeline still stands, of August 2020, even though there is currently no Reviewer. It is for Ministers to make a decision, who will replace Lord Carlile.
Safeguarding children and young people from radicalisation
Mark Chalmers of Westminster City Council., then spoke about ‘safeguarding children and young people from radicalisation.’
He started off with a profile of the local authority demographic, poverty and wealth, migrant turnover, proportion of non-English speaking households. This of itself may seem indicative of deliberate or unconscious bias.
He suggested that Prevent is not a security response, and expects that the policing role in Prevent will be reduced over time, as more is taken over by Local Authority staff and the public services. [Note: this seems inevitable after the changes in the 2019 Counter Terrorism Act, to enable local authorities, as well as the police, to refer persons at risk of being drawn into terrorism to local channel panels. Should this have happened at all, was not consulted on as far as I know]. This claim that Prevent is not a security response, appears different in practice, when Local Authorities refuse FOI questions on the basis of security exemptions in the FOI Act, Section 24(1).
Both speakers declined to accept my suggestion that Prevent and Channel is not consensual. Participation in the programme, they were adamant is voluntary and confidential. The reality is that children do not feel they can make a freely given informed choice, in the face of an authority and the severity of the referral. They also do not understand where their records go to, how confidential are they really, and how long they are kept or why.
The recently concluded legal case and lengths one individual had to go to, to remove their personal record from the Prevent national database, shows just how problematic the mistaken perception of a consensual programme by authorities is.
I knew nothing of the Prevent programme at all in 2015. I only began to hear about it once I started mapping the data flows into, across and out of the state education sector, and teachers started coming to me with stories from their schools.
I found it fascinating to hear those speak at the conference that are so embedded in the programme. They seem unable to see it objectively or able to accept others’ critical point of view as truth. It stems perhaps from the luxury of having the privilege of believing you yourself, will be unaffected by its consequences.
“Yes,” said O’Brien, “we can turn it off. We have that privilege” (1984)
There was no ground given at all for accepting that there are deep flaws in practice. That in fact ‘Prevent is having the opposite of its intended effect: by dividing, stigmatising and alienating segments of the population, Prevent could end up promoting extremism, rather than countering it’ as concluded in the 2016 report Preventing Education: Human Rights and Countering terrorism in UK Schools by Rights Watch UK .
Mark Chalmers conclusion was to suggest perhaps Prevent is not always going to be the current form, of bolt on ‘big programme’ and instead would be just like any other form of child protection, like FGM. That would mean every public sector worker, becomes an extended arm of the Home Office policy, expected to act in counter terrorism efforts.
But the training, the nuance, the level of application of autonomy that the speakers believe exists in staff and in children is imagined. The trust between authorities and people who need shelter, safety, medical care or schooling must be upheld for the public good.
No one asked, if and how children should be seen through the lens of terrorism, extremism and radicalisation at all. No one asked if and how every child, should be able to be surveilled online by school imposed software and covert photos taken through the webcam in the name of children’s safeguarding. Or labelled in school, associated with ‘terrorist.’ What happens when that prevents trust, and who measures its harm?
[click to view larger file]
Far too little is known about who and how makes decisions about the lives of others, the criteria for defining inappropriate activity or referrals, or the opacity of decisions on online content.
What effects will the Prevent programme have on our current and future society, where everyone is expected to surveil and inform upon each other? Failure to do so, to uphold the Prevent duty, becomes civic failure. How is curiosity and intent separated? How do we safeguard children from risk (that is not harm) and protect their childhood experiences, their free and full development of self?
No one wants children to be caught up in activities or radicalisation into terror groups. But is this the correct way to solve it?
This comprehensive new research by the YEIP suggests otherwise. The fact that the Home Office disengaged with the project in the last year, speaks volumes.
“The research provides new evidence that by attempting to profile and predict violent youth radicalisation, we may in fact be breeding the very reasons that lead those at risk to violent acts.” (Professor Theo Gavrielides).
Current case studies of lived experience, and history also say it is mistaken. Prevent when it comes to children, and schools, needs massive reform, at very least, but those most in favour of how it works today, aren’t the ones who can be involved in its reshaping.
“Who denounced you?” said Winston.
“It was my little daughter,” said Parsons with a sort of doleful pride. “She listened at the keyhole. Heard what I was saying, and nipped off to the patrols the very next day. Pretty smart for a nipper of seven, eh? I don’t bear her any grudge for it. In fact I’m proud of her. It shows I brought her up in the right spirit, anyway.” (1984).
The event was the launch of the European study on violent youth radicalisation from YEIP: The project investigated the attitudes and knowledge of young Europeans, youth workers and other practitioners, while testing tools for addressing the phenomenon through positive psychology and the application of the Good Lives Model.
Its findings include that young people at risk of violent radicalisation are “managed” by the existing justice system as “risks”. This creates further alienation and division, while recidivism rates continue to spiral.

