The government has launched its consultation, including on “raising the digital age of consent”, alongside examining social-media bans for under-16s, curfews, enforced breaks, age verification and VPN misuse. A further “digital childhood inquiry” was announced in January to examine these issues more broadly. The government further proposes to amend the Online Safety Act 2023, through the Crime and Policing Bill, granting itself extremely wide powers.
Unwittingly or not, the most substantial shock this week is the Department for Education seeking to grant itself sweeping powers (pp4-6) without scrutiny or evidence, to “restrict access by children of or under a specified age to specified internet services which they provide, or to specified features or functionalities of such services,” and to substantively revise Data Protection law about the, “Age of consent in relation to processing of a child’s personal data: information society services.” These include (in 214A(3)) screen time limits and the times of day at which children may access the service or a specified feature or functionality of the service i.e. curfews or shutdown laws, that provably did not work in other countries.
These powers are in effect a placeholder for what the government intends to do after the consultation closes, and appears already decided.
Key to much of the discourse is the idea of raising the “digital age of consent”. It is shorthand and misleading. It obscures its aims and what raising the age threshold of Article 8 of data protection law would — and would not — achieve.
Much of this discussion, rests on a fundamental misunderstanding of what consent actually is under data-protection law, and whether age is legally relevant to it or not. It is fundamentally the wrong vehicle to drive restrictions on use of social media by children, not least because data protection law Article 8 applies to *all* personal data from children processing under the basis of consent by an information society service, which is almost everything commercially-driven online, not only (as yet undefined) social media.
Meanwhile, the consultation is written with closed answers that lead to fixed outcomes. I suggest these need worked around via email submission to propose an alternative in any responses — and watch out, as the print-ready version and the html version have different numbering for the same questions.
Disappointingly, since the changes to the law are already written, it suggests the consultation is itself, a tick-box exercise.
The issues in summary
Ultimately, there is no such thing as a “digital age of consent” and it doesn’t work as a proxy to raise the age in Article 8 of data protection law to restrict children’s access to social media:
- Consent is not determined by age but by capacity, and its freely given, informed, power respecting, consensual characteristics;
- Consent [e.g. to use age verification] is invalid if it is compulsory or obligatory, coercive or bundled into the provision of a service ;
- Consent does not provide a valid legal ground for the processing of personal data where there is a clear power imbalance between the data subject and the controller (Recital 43);
- Article 8 requires data minimisation and Recital 57 that no additional personal data [from parent or child] be processed solely to satisfy the requirements of the Act;
- Raising the age in Article 8 until when a parent’s personal data must be processed in addition to the child’s data to authorise “consent”, will mean the personal data from more parents would be collected for more years until the child reaches the higher age threshold and from more services. Article 8 applies to *all* data processing on the basis of consent by ISS*, “offered directly to a child” not only social media.
Policy makers must not misuse data protection law for this.
Age as a Gatekeeper is no small change
Article 8 was flawed from the outset, and little public attention has been paid to how age came to be treated as a proxy for capacity in the GDPR at all. It expands data collection (by requiring parental data at all, and in this scenario for longer) and adults cannot truly consent “on behalf of” a child under pressure when AV is an obligation under a do-it-or-lose-it model when a service might be an edTech tool for example, or even a social media user group for communications used by a school.
Arguably the use of Article 8 to get tick box permission from parents is not valid consent today, never mind bringing more parents into scope, “such processing shall be lawful only if and to the extent that consent is given or authorised by the holder of parental responsibility over the child.”
Furthermore, it does nothing to empower children or to enable them to exercise their own rights, to respect or promote their rights as independent data subjects to their personhood, agency, and dignity. We could indeed redraft Article 8, but not like this. We do need to fix how and where parents permission is a poor proxy for informed, freely given consent.
As Australia has done, the age at which a designated set of social media platforms may or may not provide accounts to children is an obligation on the platforms not the child or parents, and this should be separated from thinking on data protection law.
Europe has always relied on capacity, not age, for the valid exercise of children’s rights and in its frameworks that uphold them under the law. In the era of Epstein, it is more important than ever that we do not normalise the notion that consent is nothing more than a tick box exercise.
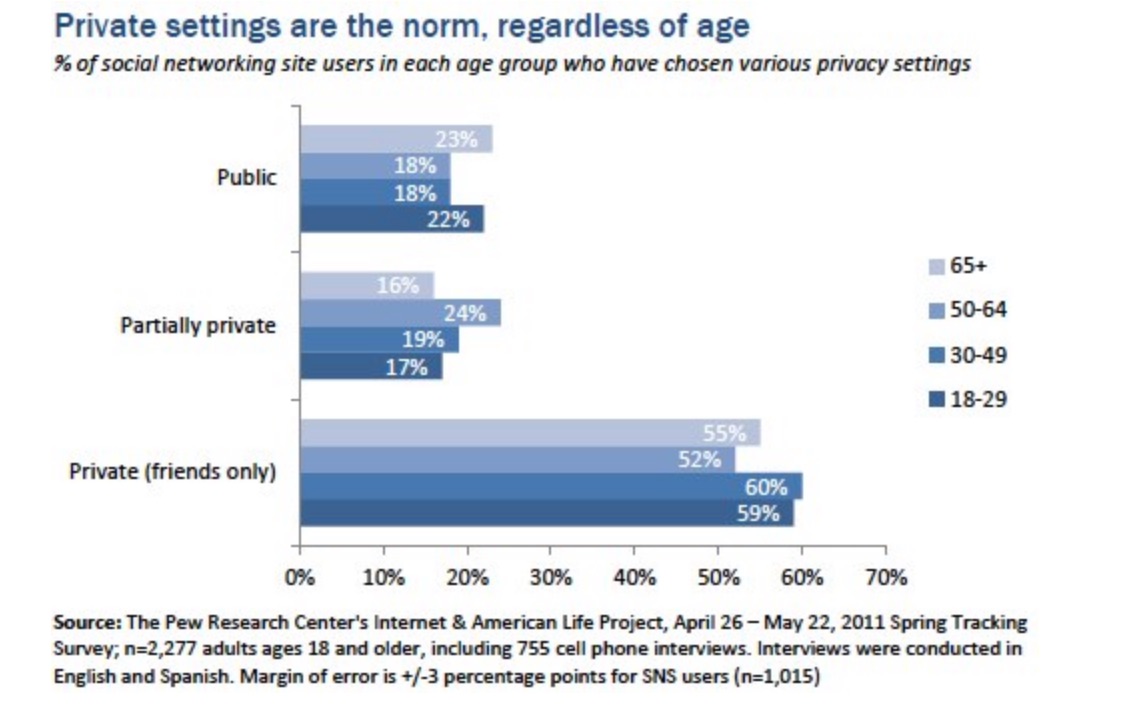
Using age as a bouncer to access online spaces, is problematic if in order to separate children from adults, websites must check the IDs of everyone to know who is not a child, to treat children differently.
The future of age as a gatekeeper in online safety is a global political agenda that affects not only children but raises questions about its wider purposes in the state control of identity, security, and informational power in the digital age with far-reaching effects on democratic participation and how anyone uses the Internet. What has been a relatively permissionless activity for anyone with the ability to be anonymous or to choose to have multiple identities managed by the corporate provider, suddenly becomes a state-ID-controlled activity. “Robust” or “highly effective” age checks require an official state-authorised ID against which an age credential is verified or assured, whether the access point is provided by a commercial third-party provider or not. Not everyone has one in the UK. Everyone will be obliged to hold a national ID of some kind in future, if “robust” age verification or assurance becomes mandatory to use social media, or go online.
The consultation says (p.40), “One way to achieve the strongest possible approach to any new age-linked restrictions would be to require every existing UK social media user to verify their age online, for example if we were to enact a ban on children from all social media.”
That means online companies no longer using their own know-your-customer log-in model, enabling us to choose how to present our identity to them, but a requirement for a robust know-your-citizen model, with obligations to be able to prove digitally who you are with some sort of “passport-level verification of your legal identity” (26:56). When it comes to the national ID for all, the Westminster government is already planning cross-government uses for Home Office such as fraud detection (01:02:00) and immigration enforcement, “much like online banking“. The enormity and reality of this requirement to have a digital ID available to use for age verification should not be seen through the rose-tinted lens of protecting children. With the imposition to have a state-accepted ID controlled via the database state, It’s the end of access to the Internet as we know it for everyone. It’s as if we’re back in 2009 with a consultation to be published next week to “explore the benefits” to people of having a national digital ID by 2029. That is the reality of “robust” age verification. How it will work, whether the ID-age-restricted access obligation will pop up based on the location of the hosted content or location of the user, is as yet unclear.
While the EU is working out its collective approach, Ireland has already announced its own plans for bringing in a state age-verification system and assumes EU presidency in July.
Meanwhile, 418 expert academics, technologists and scientists from 30 countries warned this week that social-media bans and age checks can backfire. In a statement, they called for a moratorium until evidence is clearer, citing easy circumvention, migration to risky fringe sites, and years-long infrastructure hurdles.
Rather than consider expanding state age-verification systems that will without due attention, be able to attach not only your IP address and tracking cookies but your legal identity to every search you make, and every place you visit online, we need to spend more effort on how to avoid the identification of children (by companies or others) becoming the norm.
The consultation on this topic: raising the “digital age of consent”
There are 5 narrow questions on minimum age restrictions and the effectiveness of age-verification and age-assurance technologies bundled into a few questions, and five on VPNs, each of which I will address as separate topics later.
This blogpost is only about changing the so-called and misdescribed “digital age of consent”. The proposals suggests raising the age at which parental personal details are no longer required to process a child’s data where processing is on the basis of consent.
The answers to the consultation in that section are too closed to propose a new approach, but the approach needs reframed entirely.
Replace questions 8-11 on the age of “digital consent” with a new approach. Instead of using Article 8 in data protection law, to raise the age of data processing about parents as well as the child from 13 to 16 or anything else, government should review the Age Appropriate Design Code (“the Code”) and address this via enforcement of other parts of the existing data protection law.
- Prohibit personalised targeted advertising and real-time bidding (see this video from 06:20 to understand what that is) for personal data and why intervention by Regulators is necessary (the Code only loosely currently restricts profiling);
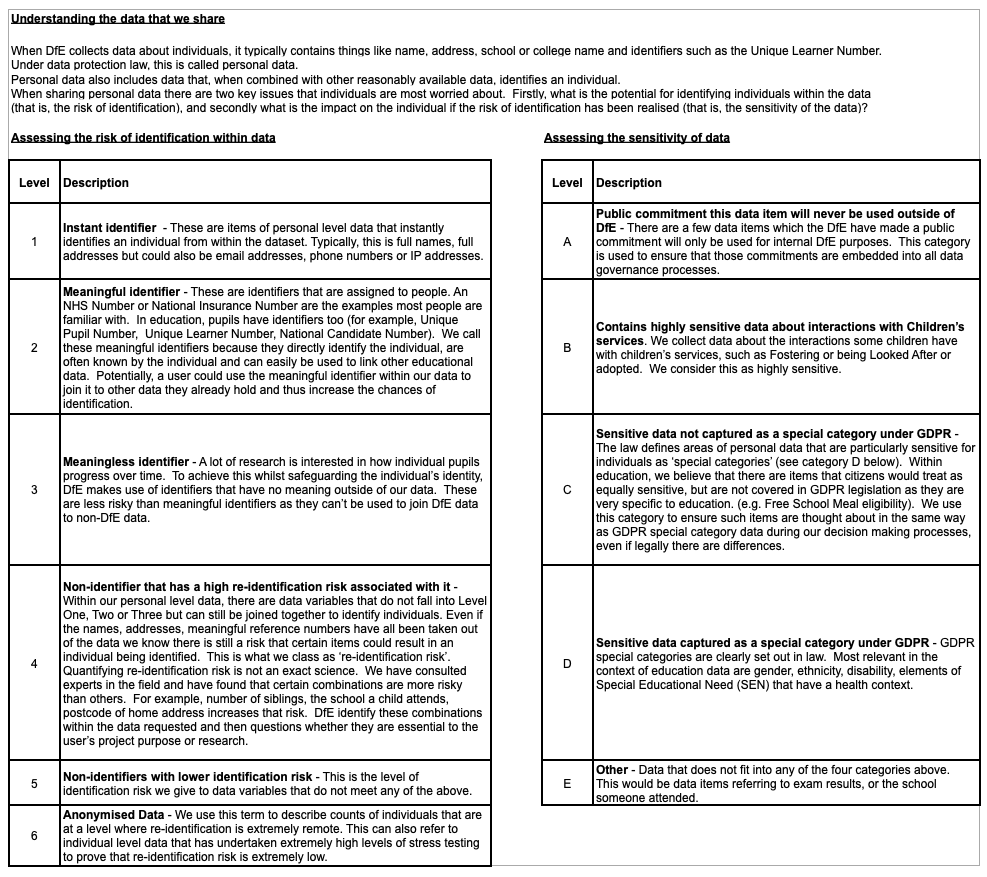
- Strictly limit data retention from or about children (the Code covers data minimisation but it’s unclear what *is* children’s data — is it forever a child’s data because the person is a child at the point of collection, or does that label expire when the child reaches age 18 and “times out” of the Code obligations?;
- Require algorithmic impact assessments more explicitly for youth-facing services (as part of the existing DPIA duty).
We must avoid the paradox of:
“We must process more personal data (age verification, and connected parental ID data) to protect children from data processing.”
The background detail of why
1. Consent in Data Protection law
Under the UK GDPR, consent is only one of six lawful bases on which personal data may be processed. Consent is not required in all circumstances. Where consent is relied upon, it must meet strict legal standards:
- Consent must be freely given, specific, unambiguous, and expressed by a clear, affirmative act by the data subject;
- Consent must be informed, which means individuals must know who is processing their data, for what purposes, what type of data is involved, and that they can withdraw consent at any time without disadvantage;
- Consent cannot be bundled, coerced, or made a condition of accessing a service (like pay or consent models, there must be real choice).
This matters because the media framing of “digital consent” treats age as if it were a standalone gateway to online access. It is not.
Consent cannot be freely given where there is compulsion, imbalance of power, or a lack of genuine choice. If processing personal data — for example for age verification or assurance — is made a mandatory condition of accessing a service, that requirement itself invalidates the ‘freely given’ nature of consent. This cannot produce valid consent under data-protection law. Recitals 42 and 43 are very explicit about this.
It is these qualities of consent and not age, that determines whether the data processing basis of consent for either the parent or the child is valid, and therefore lawful, or not. It’s not enough to tick “agree”.
2. Article 8 is narrow in scope and not about social media as such
The misunderstanding of Article 8 of the UK GDPR is not primarily about age. It is about scope.
Article 8 applies only where three specific conditions are met:
Article 8 is only relevant where (a) personal data is processed (b) by an information society service (ISS)*, AND that data is processed (c) on the basis of consent. If a website or service processes personal data on another data protection law lawful basis — such as legitimate interests, performance of a contract, or compliance with a legal obligation — then the consent rules, and the age rules attached to them in Article 8, do not apply.
If any of these conditions is absent, Article 8 is irrelevant. It does not govern children’s data processing in general, and it does not create a general age rule for online services or social-media access.
3. Article 8 does not create a “digital age of consent”
What Article 8 says is that below the national age threshold set in domestic law (between 13 and 16, depending on the country), parental authorisation is required to process a younger child’ personal data, in practice this means collecting personal details from them as well as personal data from the child to connect the relationship. Again, this applies only where the condition applies that consent is the lawful basis being relied upon.
Crucially, Article 8 does not impose a positive obligation on services to obtain consent from a child at a particular age. It creates a negative duty from when a parent’s permission as authorisation in place of or a “pseudo” consent (and the extra parental personal data) is no longer required for processing, and only for processing by an ISS*.
Let’s assume the same parents who agree to children’s social media use and help them sign up today by providing parental permission (in the UK under 13) will do so in future. What this change would mean for them, is that it would require those parents’ data to be processed for longer, for more years. Instead of requiring parents’ personal data as well as the child’s only aged up to 13 it would require the parents’ data to continue to be processed up to the newly raised age limit in addition to that child’s own data. Let’s assume the number of parents who agree at each year up to the newly raised limit increases. The companies now no longer only get the child’s personal data after age 13, but parents’ data too. And this applies to far more companies as ISS than social media. Just what we don’t want.
4. Proposals to “raise the digital age of consent” in order to restrict children’s access to social media are therefore conceptually flawed
Against this background, proposals to restrict more children’s access to social media by “raising the digital age of consent” are conceptually flawed. They attempt to use data-protection law, which regulates the obligations of data controllers (service providers), as a proxy for regulating users permissions to access content. There is in fact no such thing as a digital age of consent because it is an obligation to hand over the parents’ data bundled with the child’s as a condition of the service, and not freely given.
The GDPR does not restrict who may access online services. It regulates the conditions under which their personal data may be processed. As long as the child is over the age of the Terms and Conditions set by the provider, the child can use the service at any age if it doesn’t process personal data on the basis of consent.
There is also a basic logical contradiction at the heart of many such proposals. A service cannot know whether a user is a child or an adult without processing personal data that reveals age, date of birth, or an age credential. Prohibiting or restricting the processing of children’s data at younger ages, while simultaneously requiring services to identify children in order to exclude them, is incoherent.
It is also incompatible with the duty towards data minimisation and recital 38 to protect children from excessive data processing. Recital 57 further explains why this attempt to misuse data protection law is flawed. It would require more data to be collected, to ascertain age, than may otherwise be necessary to process.
“If the personal data processed by a controller do not permit the controller to identify a natural person, the data controller should not be obliged to acquire additional information in order to identify the data subject for the sole purpose of complying with any provision of this Regulation.”
*Definition: What is an ISS? (an information society service)
The basic definition of an ISS in the GDPR is based on Article 1(1)(b) of Directive (EU) 2015/1535:
“any service normally provided for remuneration, at a distance, by electronic means and at the individual request of a recipient of services.
For the purposes of this definition:
(i) ‘at a distance’ means that the service is provided without the parties being simultaneously present;
(ii) ‘by electronic means’ means that the service is sent initially and received at its destination by means of electronic equipment for the processing (including digital compression) and storage of data, and entirely transmitted, conveyed and received by wire, by radio, by optical means or by other electromagnetic means;
(iii) ‘at the individual request of a recipient of services’ means that the service is provided through the transmission of data on individual request.”