King: “Who is king here? I remind you, so you remember that? I do not remember any promises. I do not remember anything, except that you are my servant.” Anna: “No, your majesty, that is not true.”
This is the question Matthew Honeyman of the policy team at The King’s Fund asked in a mix of fact and fiction in his recent feature that describes a future scenario in which a widespread breakdown in trust has lasting harmful consequences for public interest research.
He argues that, ‘the health system needs to work hard to make sure the scenario achieved is one that realises the full potential of using health data, rather than seeing people opt out because they don’t see the benefits or their trust ebbs away.’
Anyone attending umpteen public engagement events in 2014-15 about using care.data in the health system, knows it was clear that understanding the benefits was not the real issue, no matter how often the NHS England leadership team said that was the outcome.
People understood how data are used to support commissioning and how everyone’s treatment can be compared to see whether care is equitable. What the leadership was unwilling to answer was why individual identifiable data extraction was the only solution they would accept in order to achieve those ‘benefits’. Because the benefits were not hard to understand. It was just hard to accept they outweighed the risks and loss people felt giving up their confidentiality.
Many people simply didn’t trust that these data would be used to benefit them as individuals and society, but that ‘the public interest’ would be interpreted by government as finding the lowest cost, minimal service options that would meet the demands of the NHS constitution on service delivery, or worse, that data would be used to best analyse the GP care ‘market’ and used to deliver private service provision and reshape the national primary care system.
There were many questions asked that never received answers.
Questions such as:
1. Clearly stating what parts of our personal, confidential records, sensitive or otherwise are to be extracted now, and How will we be informed if that scope changes in future and we then object if we want data not to be used at all? Since the plan right now is we could only ask for it to be ‘pseudonymised’?
2. What do we do, if we object to any use on any grounds, such as ethical or conscientious grounds for objection to use in research about contraceptives or pregnancy terminations?
3. How will we know in future that there are no plans to release my data outside the UK and EU, as HES has been in the past, and if that changes what guarantee is there we could object at that point?
4. How will objection management (storing our opt out decision) be implemented with other data sharing? (SCR, Electronic Prescription Service, OOH access, Proactive care at local level) so we understand it?
5.Will the views of Dr. Mike Bewick, deputy medical director at NHS England, also be ignored, who said parts (referring to commercial use) should be ‘opt-in’ only? [Pulse, June 2014]
6. What will ensure opt out remains more than just Mr.Hunt’s word, if it has no legislative backing?
Leadership underestimated the damage done to confidence since the public found out who their data had been given to without their knowledge or consent over several years. And ignored the difficult questions.
To insist that the public ‘didn’t get it’, deriding participants effectively as too stupid to see the purposes of the leadership plan, simply wasn’t true, especially of the people who came to the events as they did so with some idea of what was at stake, understanding or questions.
People ‘get it’ more than some want to admit. But that outcome doesn’t suit what they wanted.
Even for commissioning purposes it was previously unclear how these datasharing reasons are justified when the Caldicott Review said extracting identifiable data for risk stratification or commissioning could not be assumed under some sort of ‘consent deal’ which was trying to work around confidentiality.
“The Review Panel found that commissioners do not need dispensation from confidentiality, human rights and data protection law…” [The Information Governance review, ch7]
What *is* still an issue of truly communicating understanding, is where information is not being fully transparent. Particularly around planned future scope change and how signing up to one thing today, might mean something quite different in future.
care.data as a brand may be defunct, but the use of our health data in all its forms from all souces is still very much on the table in play.
care.data risks becoming pseudonymous with an eternal illusion of control and consent.
Now models of consent are under consideration again.
Promises made and the Public Interest
Promises made must be kept if the giver is to remain trustworthy. Agreements must be consensual if they are to be valid.
So what happens when an imbalance of power means that the promise-maker has the opportunity to revoke a promise made, and the subject is told they should be happy that they have been left with the outcome of this benevolent choice, made in their best interest?
In the 1956 classic, The King and I, Anna makes it quite clear. She is in charge of her own choices. And left with none that are consensual, aligned with what she wants, she will take the only way out that is left to her, to deny the King what he wants, and she plans to leave, even though she would rather not.
What if promises are made by the State and ‘in your best interest’ is intended to be the Public Interest? What happens if people decide that the choice on offer ‘in the public interest’ and their personal interests conflict, and they choose to leave?
This is one risk of some of the proposals in the current Caldicott consultation on “New data security standards and opt-out models for health and social care”.
2.2% of people, who knew about care.data plans in 2014, that is 2.2 per cent, one in forty-five, or 1.2 million of the NHS’s 56 million patients opted out of their confidential records being handed over to the national body the Health and Social Care Information Centre and from there being handed over to commercial companies among other third parties and from there…. etcetera etcetera etcetera.
And why? Because we have been given an artificial choice. The choice we have been left with, is as data subjects we are told we should be happy to be left with the outcome of a benevolent choice, made in our best interest by those in power. Real choice is not on offer if “anonymised” secondary use is mandatory.
The Proposed Consent/Opt-out Model offers choices
You can give your views here by the deadline of September 7th, and can choose to reply only to all or part of the consultation, questions on consent are pages 5-7, questions 11-15: https://consultations.dh.gov.uk/information/ndg-review-of-data-security-consent-and-opt-outs/consultation/subpage.2016-06-22.1760366280/view
‘This choice could be presented as two separate opt-outs. Or there could be a single opt-out covering personal confidential information being used both in running the health and social care system and to support research and improve treatment and care.’
However, The opt-out will not apply to anonymised information.
I would like to understand what ‘anonymised’ means in these discussions. Is it aligned with the newly published Anonymisation Decision Making Network, from UKAN? Anonymous and pseudonymous are often used interchangeably in discussions of health data secondary use. They are not the same thing at all.
What anonymous means is still unclear because language in the past care.data discussions over what ‘anonymous’ really means was conflated with pseudonymous, with deidentified or to mean any data that was not in the category of personal confidential data. [NHS England care.data presentation, pp7-10] Can we trust that anonymous means anonymous, i.e. what NHS England labelled on p.7 as ‘green’ data – aggregated and can be published, not what it called ‘amber data’, or pseudonymous potentially identifying data, and that cannot be freely published. And what guarantee has the public, that definition will not be changed?
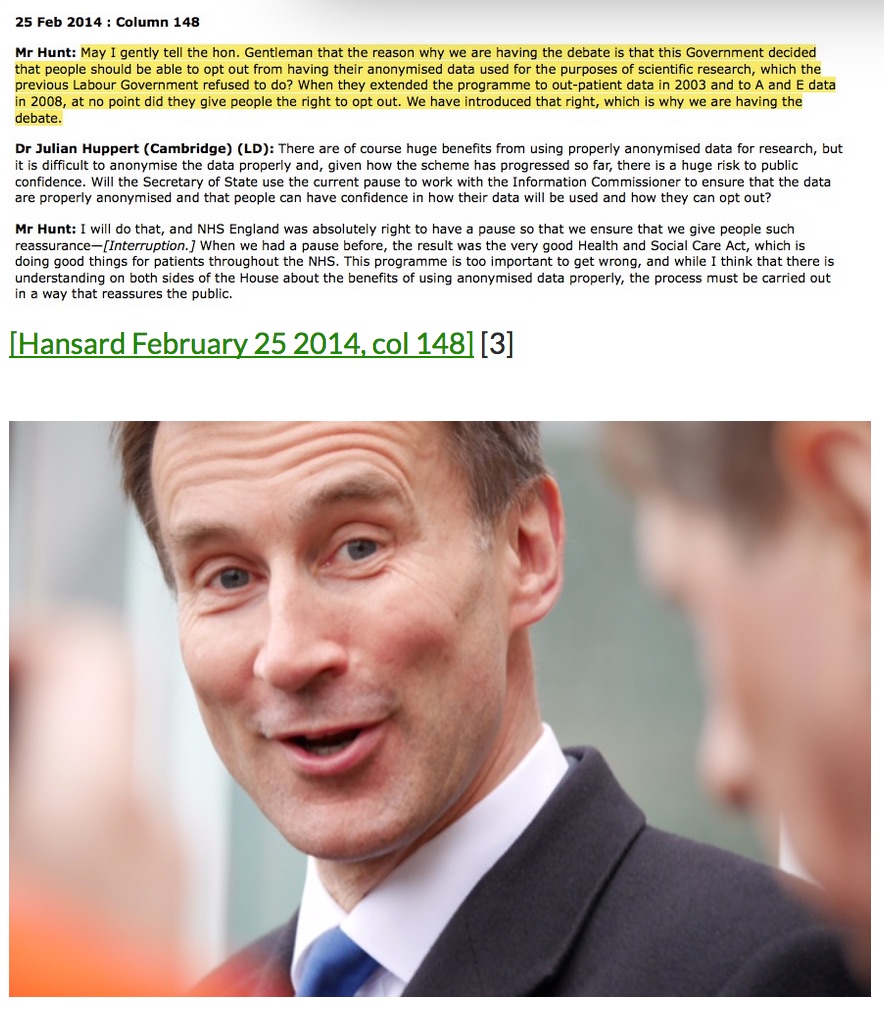
I would challenge any policy maker who thinks revoking the promise made by the Secretary of State Jeremy Hunt, under care.data was a good idea. It was in fact not only a promise to opt out of identifiable data uses but anonymous use too:
“we said that if we are going to use anonymised data for the benefit of scientific discovery in the NHS, people should have the right to opt out.”
[Hansard, February 2014, col.147 Jeremy Hunt]
Suggesting therefore that all data would be mandatory to extract from primary care to a central database, and the only control patients would have, is to stop identifiable data leaving the palace walls, but that de-identifed data or anonymous data would be beyond our control is not only unethical but would break past promises made. It will also enable identifiable data to be used ‘inside’ or to be linked with all sorts of other data ‘inside’ before the identifiers being removed and ‘anonymous data’ released outside.
If people object to their data used in research, whether on conscientious or private grounds, is that to be disrespected?
And once this consultation is complete, and the new model is in place, the Review recommends that existing arrangements should be replaced. This could mean choices made under care.data are revoked. “Some patients will have already made choices about the sharing of their information under the existing opt-out framework, and it will need to be decided how these opt-outs will be treated under any new consent/opt-out model.”
If people objected to their data used in research, whether on conscientious or private grounds, is that to be overruled and be valid? How on earth would they justify overruling GPs data controller duties to patient confidentiality and control?
The difference between use and sue, is only a matter of position.
The public benefit will be squandered if purposes continue to be conflated
Very recently, at an event about academic use of public data I was told by an eminent and well respected academic that if ‘he who shall remain nameless hadn’t sold the DH a plan to make money out of selling public data to him and his mates, we wouldn’t be in this mess to start with.‘ End quote.
Intentions of current leadership may be well meant, but refusing to see fatal flaws in the national plan will make it fail. It’s the elephant in the room few want to acknowledge, but this does not make it any less real.
Scope change cannot be open-ended and be trusted. We cannot sign up to one thing with meaningful consent, without guarantees of what that means for the future. It’s said and repeated and said again. It must be taken seriously. It’s what happened to school pupils data, given in trust, now given out to journalists, charities, commercial companies and others beyond our control. Consent is an illusion and not valid.
It goes straight back to the original care.data plan, of trust us, give us all your data, then we will do what we want anyway.
The opt out on offer at Christmas 2014 was to restrict identifiable data sharing. There was “no need” to take into account individual objection to pseudonymous data sharing said the September 13th NHS England directions. There was no business case for the longest time. Most of the questions, the Caldicott tests, remain unanswered.
This consultation is unlikely to bring a vast reponse rate, given the limited communication it is getting. There have already been consultation responses. The care.data events were held. Public feedback was clear. Their questions and concerns are being ignored. In fact, even the care.data listening events’ feedback seems now impossble to find.(care.data documents at NHS England leads from ‘Care.data listening exercise and action plan’ to a 404)
Leadership continues to argue that they are right, that there are long term benefits and it is part of a bigger vision for healthcare. Even that is described in terms that are at best woolly.
In order to have access to quality information, with integrity and completeness, there can be no shortcuts in ethical extraction or use. Lack of a techncal solution to using all data in truly anonymous ways is a choice, which should not default to making individual identifiable use a requirement.
Shortsightedness of how much people value privacy is stopping them from seeing how this will undermine what they want to achieve. And potentially will store up bigger problems for future.
King: “Pairs of male elephants to be released into the forests of America. There it is hoped that they will grow in number and the people can tame them and use them as beasts of burden.”
Anna: “But your majesty, I don’t think you mean pairs of MALE elephants.”
An illusion of control: power imbalance of service provider and service user
So what happens if those in charge determine that no one should be able to withhold access to their data?
The other, less transparent, less ethical way to achieve the same purpose, is to insist that in using a service, users must agree to secondary uses of their data. To say that “no one who uses a public service should be allowed to opt out of sharing their records. Nor can people rely on their record being anonymised.”
If in order to use the service, they demand our data is also used for secondary purposes, there can be no semblance of ethical consent.
And the final part of control, is in the event of complaint, being able to ask for redress, What intervention can be meaningful to exercise control of who has that data for legitimate and necessary purposes if we ask for redress, if only the ICO can challenge the outcome of the decision, which takes interminably long, by which time you may have needed the service and data has long and irrecoverably gone to third parties.
The risk of ‘control’ being handed to patients in the NHS by the people who currently control it, and under their terms and conditions, with its current degree of transparency, is that it is very likely an illusion. Real control will only be meaningful with real transparency of use and users, and communication of any change.
Control of our own data is what most people want. But it will only meet public expectations if it also honest, and meets other conditions they key to which is that consent to one thing today, does not mean consent to more tomorrow:
- purposes for which data are shared are clear and limited
- users of the data are defined, described and designated
What health data will mean in future will not be the same as it does today. How can we really know what we sign up to means and what we are agreeing to take control *of*?
Do we trust private companies who are working for-profit to take decisions with the greatest ethical interest, rather than the commercially driven one?
Do we trust a system that cannot tell us what scope changes to use or users will be made in future? The care.data roadmap plans change to purposes, users and use, so how can we have meaningful control of that?
Control is often offered on data use in the form of a privacy policy. We ‘agree’ to the small print. Privacy policies are a mess that no one reads, yet we continue to accept them because there is nothing better. While there is value in work done to improve them, a simple privacy policy for care.data is not a solution. It’s not even on offer.
There is no simple, clear plan which says, this is what purposes and users of your personal data will be restricted to. This is what we will do to inform you if we changes those purposes. This is how you can then object and have your data completely removed at that point. This applies to all your data.
If leadership wants to foster genuine trust we need something better than an illusion of consent and an illusion of honesty. Public trust will not be built on a broken promise.
****
Don’t forget: You can give your views here, and can choose to reply to it all, or only to the part on consent pages 5-7, questions 11-15, by the deadline of September 7th: https://consultations.dh.gov.uk/information/ndg-review-of-data-security-consent-and-opt-outs/consultation/subpage.2016-06-22.1760366280/view
image: https://www.flickr.com/photos/vaishali-ahuja CC BY-NC 2.0