Bird and Bird GDPR Tracker [Shows how and where GDPR has been supplemented locally, highlighting where Member States have taken the opportunities available in the law for national variation.]
DP Bill’s new immigration exemption can put EU citizens seeking a right to remain at considerable disadvantage [09.10] re: Schedule 2, paragraph 4, new Immigration exemption.
On Adequacy: Draconian powers in EU Withdrawal Bill can negate new Data Protection law[13.09]
Queen’s Speech, and the promised “Data Protection (Exemptions from GDPR) Bill” [29.06]
defenddigitalme
Response to the Data Protection Bill debate and Green Paper on Online Strategy [11.10.2017]
Queen’s speech: safeguarding children, data, and digital rights[22.6]
Jon Baines
Serious DCMS error about consent data protection[11.08]
Eoin O’Dell
The UK’s Data Protection Bill 2017: repeals and compensation – updated: On DCMS legislating for Art 82 GDPR. [14.09]
Data Protection Bill Consultation: General Data Protection Regulation Call for Views on exemptions
New Data Protection Bill: Our planned reforms [PDF]952KB, 30 pages
London Economics: Research and analysis to quantify benefits arising from personal data rights under the GDPR [PDF]3.76MB189 pages
ESRC joint submissions on EU General Data Protection Regulation in the UK – Wellcome led multi org submission plus submission from British Academy / Erdos [link]
Minister for Digital Matt Hancock’s keynote address to the UK Internet Governance Forum, 13 September [link].
“…the Data Protection Bill, which will bring our data protection regime into the twenty first century, giving citizens more sovereignty over their data, and greater penalties for those who break the rules.
“With AI and machine learning, data use is moving fast. Good use of data isn’t just about complying with the regulations, it’s about the ethical use of data too.
“So good governance of data isn’t just about legislation – as important as that is – it’s also about establishing ethical norms and boundaries, as a society. And this is something our Digital Charter will address too.”
The Queen’s Speech promised new laws to ensure that the United Kingdom retains its world-class regime protecting personal data. And the government proposes a new digital charter to make the United Kingdom the safest place to be online for children.
Improving online safety for children should mean one thing. Children should be able to use online services without being used by them and the people and organisations behind it. It should mean that their rights to be heard are prioritised in decisions about them.
As Sir Tim Berners-Lee is reported as saying, there is a need to work with companies to put “a fair level of data control back in the hands of people“. He rightly points out that today terms and conditions are “all or nothing”.
There is a gap in discussions that we fail to address when we think of consent to terms and conditions, or “handing over data”. It is that this assumes that these are always and can be always, conscious acts.
For children the question of whether accepting Ts&Cs giving them control and whether it is meaningful becomes even more moot. What are the agreeing to? Younger children cannot give free and informed consent. After all most privacy policies standardly include phrases such as, “If we sell all or a portion of our business, we may transfer all of your information, including personal information, to the successor organization,” which means in effect that “accepting” a privacy policy today, is effectively a blank cheque for anything tomorrow.
The GDPR requires terms and conditions to be laid out in policies that a child can understand.
The current approach to legislation around children and the Internet is heavily weighted towards protection from seen threats. The threats we need to give more attention to, are those unseen.
Our lives as measured in our behaviours and opinions, purchases and likes, are connected by trillions of sensors. My parents may have described using the Internet as going online. Today’s online world no longer means our time is spent ‘on the computer’, but being online, all day every day. Instead of going to a desk and booting up through a long phone cable, we have wireless computers in our pockets and in our homes, with functionality built-in to enable us to do other things; make a phonecall, make toast, and play. In a smart city surrounded by sensors under pavements, in buildings, cameras and tracking everywhere we go, we are living ever more inside an overarching network of cloud computers that store our data. And from all that data decisions are made, which adverts to show us, on which network sites, what we get offered and do not, and our behaviours and our conscious decision-making may be nudged quite invisibly.
Data about us, whether uniquely identifiable or not, is all too often collected passively, IP Address, linked sign-ins that extract friends lists, and some decide if we can either use the thing or not. It’s part of the deal. We get the service, they get to trade our identity, like Top Trumps, behind the scenes. But we often don’t see it, and under GDPR, there should be no contractual requirement as part of consent. I.e. agree or don’t get the service, is not an option.
As yet, we have not had debate in the UK what that means in concrete terms, and if we do not soon, we risk it becoming an afterthought that harms more than helps protect children’s privacy, and therefore their digital identity.
I think of five things needed by policy shapers to tackle it:
In depth understanding of what ‘online’ and the Internet mean
Consistent understanding of what threat models and risk are connected to personal data, which today are underestimated
A grasp of why data privacy training is vital to safeguarding
Confront the idea that user regulation as a stand-alone step will create a better online experience for users, when we know that perceived problems are created by providers or other site users
Siloed thinking that fails to be forward thinking or join the dots of tactics across Departments into cohesive inclusive strategy
If the government’s new “major new drive on internet safety” involves the world’s largest technology companies in order to make the UK the “safest place in the world for young people to go online,” then we must also ensure that these strategies and papers join things up and above all, a technical knowledge of how the Internet works needs to join the dots of risks and benefits in order to form a strategy that will actually make children safe, skilled and see into their future.
When it comes to children, there is a further question over consent and parental spyware. Various walk-to-school apps, lauded by the former Secretary of State two years running, use spyware and can be used without a child’s consent. Guardian Gallery, which could be used to scan for nudity in photos on anyone’s phone that the ‘parent’ phone holder has access to install it on, can be made invisible on the ‘child’ phone. Imagine this in coercive relationships.
If these technologies and the online environment are not correctly assessed with regard to “online safety” threat models for all parts of our population, then they fail to address the risk for the most vulnerable who need it.
What will the GDPR really mean for online safety improvement? What will it define as online services for remuneration in the IoT? And who will be considered as children, “targeted at” or “offered to”?
An active decision is required in the UK. Will 16 remain the default age needed for consent to access Information Society Services, or will we adopt 13 which needs a legal change?
As banal as these questions sound they need close attention paid, and clarity, between now and May 25, 2018 if the UK is to be GDPR ready for providers of online services to know who and how they should treat Internet access, participation and age [parental] verification.
How will the “controller” make “reasonable efforts to verify in such cases that consent is given or authorised by the holder of parental responsibility over the child”, and “taking into consideration available technology”.
These are fundamental questions of what the Internet is and means to people today. And if the current government approach to security is anything to go by, safety will not mean what we think it will mean.
It will matter how these plans join up. Age verification was not being considered in UK law in relation to how we would derogate GDPR, even as late as in October 2016 despite age verification requirements already in the Digital Economy Bill. It shows a lack of joined up digital thinking across our government and needs addressed with urgency to get into the next Parliamentary round.
In recent draft legislation I am yet to see the UK government address Internet rights and safety for young people as anything other than a protection issue, treating the online space in the same way as offline, irl, focused on stranger danger, and sexting.
The UK Digital Strategy commits to the implementation of the General Data Protection Regulation by May 2018, and frames it as a business issue, labelling data as “a global commodity” and as such, its handling is framed solely as a requirements needed to ensure “that our businesses can continue to compete and communicate effectively around the world” and that adoption “will ensure a shared and higher standard of protection for consumers and their data.”
The Digital Economy Bill, despite being a perfect vehicle for this has failed to take on children’s rights, and in particular the requirements of GDPR for consent at all. It was clear if we were to do any future digital transactions we need to level up to GDPR, not drop to the lowest common denominator between that and existing laws.
It was utterly ignored. So were children’s rights to have their own views heard in the consultation to comment on the GDPR derogations for children, with little chance for involvement from young people’s organisations, and less than a monthto respond.
We must now get this right in any new Digital Strategy and bill in the coming parliament.
What would it mean for you to trust an Internet connected product or service and why would you not?
What has damaged consumer trust in products and services and why do sellers care?
What do we want to see different from today, and what is necessary to bring about that change?
These three pairs of questions implicitly underpinned the intense day of #iotmark discussion at the London Zoo last Friday.
The questions went unasked, and could have been voiced before we started, although were probably assumed to be self-evident:
Why do you want one at all [define the problem]?
What needs to change and why [define the future model]?
How do you deliver that and for whom [set out the solution]?
If a group does not agree on the need and drivers for change, there will be no consensus on what that should look like, what the gap is to achieve it, and even less on making it happen.
So who do you want the trustmark to be for, why will anyone want it, and what will need to change to deliver the aims? No one wants a trustmark per se. Perhaps you want what values or promises it embodies to demonstrate what you stand for, promote good practice, and generate consumer trust. To generate trust, you must be seen to be trustworthy. Will the principles deliver on those goals?
The Open IoT Certification Mark Principles, as a rough draft was the outcome of the day, and are available online.
Here’s my reflections, including what was missing on privacy, and the potential for it to be considered in future.
I’ve structured this first, assuming readers attended the event, at ca 1,000 words. Lists and bullet points. The background comes after that, for anyone interested to read a longer piece.
Many thanks upfront, to fellow participants, to the organisers Alexandra D-S and Usman Haque and the colleague who hosted at the London Zoo. And Usman’s Mum. I hope there will be more constructive work to follow, and that there is space for civil society to play a supporting role and critical friend.
The mark didn’t aim to fix the IoT in a day, but deliver something better for product and service users, by those IoT companies and providers who want to sign up. Here is what I took away.
I learned three things
A sense of privacy is not homogenous, even within people who like and care about privacy in theoretical and applied ways. (I very much look forward to reading suggestions promised by fellow participants, even if enforced personal openness and ‘watching the watchers’ may mean ‘privacy is theft‘.)
Awareness of current data protection regulations needs improved in the field. For example, Subject Access Requests already apply to all data controllers, public and private. Few have read the GDPR, or the e-Privacy directive, despite importance for security measures in personal devices, relevant for IoT.
I truly love working on this stuff, with people who care.
And it reaffirmed things I already knew
Change is hard, no matter in what field.
People working together towards a common goal is brilliant.
Group collaboration can create some brilliantly sharp ideas. Group compromise can blunt them.
Some men are particularly bad at talking over each other, never mind over the women in the conversation. Women notice more. (Note to self: When discussion is passionate, it’s hard to hold back in my own enthusiasm and not do the same myself. To fix.)
The IoT context, and risks within it are not homogenous, but brings new risks and adverseries. The risks for manufacturers and consumers and the rest of the public are different, and cannot be easily solved with a one-size-fits-all solution. But we can try.
Concerns I came away with
If the citizen / customer / individual is to benefit from the IoT trustmark, they must be put first, ahead of companies’ wants.
If the IoT group controls both the design, assessment to adherence and the definition of success, how objective will it be?
The group was not sufficiently diverse and as a result, reflects too little on the risks and impact of the lack of diversity in design and effect, and the implications of dataveillance .
Critical minority thoughts although welcomed, were stripped out from crowdsourced first draft principles in compromise.
More future thinking should be built-in to be robust over time.
What was missing
There was too little discussion of privacy in perhaps the most important context of IoT – inter connectivity and new adversaries. It’s not only about *your* thing, but things that it speaks to, interacts with, of friends, passersby, the cityscape , and other individual and state actors interested in offense and defense. While we started to discuss it, we did not have the opportunity to discuss sufficiently at depth to be able to get any thinking into applying solutions in the principles.
One of the greatest risks that users face is the ubiquitous collection and storage of data about users that reveal detailed, inter-connected patterns of behaviour and our identity and not seeing how that is used by companies behind the scenes.
What we also missed discussing is not what we see as necessary today, but what we can foresee as necessary for the short term future, brainstorming and crowdsourcing horizon scanning for market needs and changing stakeholder wants.
Future thinking
Here’s the areas of future thinking that smart thinking on the IoT mark could consider.
We are moving towards ever greater requirements to declare identity to use a product or service, to register and log in to use anything at all. How will that change trust in IoT devices?
Single identity sign-on is becoming ever more imposed, and any attempts for multiple presentation of who I am by choice, and dependent on context, therefore restricted. [not all users want to use the same social media credentials for online shopping, with their child’s school app, and their weekend entertainment]
Is this imposition what the public wants or what companies sell us as what customers want in the name of convenience? What I believe the public would really want is the choice to do neither.
There is increasingly no private space or time, at places of work.
Limitations on private space are encroaching in secret in all public city spaces. How will ‘handoffs’ affect privacy in the IoT?
There is too little understanding of the social effects of this connectedness and knowledge created, embedded in design.
What effects may there be on the perception of the IoT as a whole, if predictive data analysis and complex machine learning and AI hidden in black boxes becomes more commonplace and not every company wants to be or can be open-by-design?
Ubiquitous collection and storage of data about users that reveal detailed, inter-connected patterns of behaviour and our identity needs greater commitments to disclosure. Where the hand-offs are to other devices, and whatever else is in the surrounding ecosystem, who has responsibility for communicating interaction through privacy notices, or defining legitimate interests, where the data joined up may be much more revealing than stand-alone data in each silo?
Define with greater clarity the privacy threat models for different groups of stakeholders and address the principles for each.
What would better look like?
The draft privacy principles are a start, but they’re not yet aspirational as I would have hoped. Of course the principles will only be adopted if possible, practical and by those who choose to. But where is the differentiator from what everyone is required to do, and better than the bare minimum? How will you sell this to consumers as new? How would you like your child to be treated?
The wording in these 5 bullet points, is the first crowdsourced starting point.
The supplier of this product or service MUST be General Data Protection Regulation (GDPR) compliant.
This product SHALL NOT disclose data to third parties without my knowledge.
I SHOULD get full access to all the data collected about me.
I MAY operate this device without connecting to the internet.
My data SHALL NOT be used for profiling, marketing or advertising without transparent disclosure.
Yes other points that came under security address some of the crossover between privacy and surveillance risks, but there is as yet little substantial that is aspirational to make the IoT mark a real differentiator in terms of privacy. An opportunity remains.
It was that and how young people perceive privacy that I hoped to bring to the table. Because if manufacturers are serious about future success, they cannot ignore today’s children and how they feel. How you treat them today, will shape future purchasers and their purchasing, and there is evidence you are getting it wrong.
The timing is good in that it now also offers the opportunity to promote consistent understanding, and embed the language of GDPR and ePrivacy regulations into consistent and compatible language in policy and practice in the #IoTmark principles.
User rights I would like to see considered
These are some of the points I would think privacy by design would mean. This would better articulate GDPR Article 25 to consumers.
Data sovereignty is a good concept and I believe should be considered for inclusion in explanatory blurb before any agreed privacy principles.
Goods should by ‘dumb* by default’ until the smart functionality is switched on. [*As our group chair/scribe called it] I would describe this as, “off is the default setting out-of-the-box”.
Privact by design. Deniability by default. i.e. not only after opt out, but a company should not access the personal or identifying purchase data of anyone who opts out of data collection about their product/service use during the set up process.
The right to opt out of data collection at a later date while continuing to use services.
A right to object to the sale or transfer of behavioural data, including to third-party ad networks and absolute opt-in on company transfer of ownership.
A requirement that advertising should be targeted to content, [user bought fridge A] not through jigsaw data held on users by the company [how user uses fridge A, B, C and related behaviour].
An absolute rejection of using children’s personal data gathered to target advertising and marketing at children
Background: Starting points before privacy
After a brief recap on 5 years ago, we heard two talks.
The first was a presentation from Bosch. They used the insights from the IoT open definition from 5 years ago in their IoT thinking and embedded it in their brand book. The presenter suggested that in five years time, every fridge Bosch sells will be ‘smart’. And the second was a fascinating presentation, of both EU thinking and the intellectual nudge to think beyond the practical and think what kind of society we want to see using the IoT in future. Hints of hardcore ethics and philosophy that made my brain fizz from Gerald Santucci, soon to retire from the European Commission.
The principles of open sourcing, manufacturing, and sustainable life cycle were debated in the afternoon with intense arguments and clearly knowledgeable participants, including those who were quiet. But while the group had assigned security, and started work on it weeks before, there was no one pre-assigned to privacy. For me, that said something. If they are serious about those who earn the trustmark being better for customers than their competition, then there needs to be greater emphasis on thinking like their customers, and by their customers, and what use the mark will be to customers, not companies. Plan early public engagement and testing into the design of this IoT mark, and make that testing open and diverse.
To that end, I believe it needed to be articulated more strongly, that sustainable public trust is the primary goal of the principles.
Trust that my device will not become unusable or worthless through updates or lack of them.
Trust that my device is manufactured safely and ethically and with thought given to end of life and the environment.
Trust that my source components are of high standards.
Trust in what data and how that data is gathered and used by the manufacturers.
Fundamental to ‘smart’ devices is their connection to the Internet, and so the last for me, is therefore key to successful public perception and it actually making a difference, beyond the PR value to companies. The value-add must be measured from consumers point of view.
All the openness about design functions and practice improvements, without attempting to change privacy infringing practices, may be wasted effort. Why? Because the perceived benefit of the value of the mark, will be proportionate to what risks it is seen to mitigate.
Why?
Because I assume that you know where your source components come from today. I was shocked to find out not all do and that ‘one degree removed’ is going to be an improvement? Holy cow, I thought. What about regulatory requirements for product safety recalls? These differ of course for different product areas, but I was still surprised. Having worked in global Fast Moving Consumer Goods (FMCG) and food industry, semiconductor and optoelectronics, and medical devices it was self-evident for me, that sourcing is rigorous. So that new requirement to know one degree removed, was a suggested minimum. But it might shock consumers to know there is not usually more by default.
Customers also believe they have reasonable expectations of not being screwed by a product update, left with something that does not work because of its computing based components. The public can take vocal, reputation-damaging action when they are let down.
While these are visible, the full extent of the overreach of company market and product surveillance into our whole lives, not just our living rooms, is yet to become understood by the general population. What will happen when it is?
The Internet of Things is exacerbating the power imbalance between consumers and companies, between government and citizens. As Wendy Grossman wrote recently, in one sense this may make privacy advocates’ jobs easier. It was always hard to explain why “privacy” mattered. Power, people understand.
That public discussion is long overdue. If open principles on IoT devices mean that the signed-up companies differentiate themselves by becoming market leaders in transparency, it will be a great thing. Companies need to offer full disclosure of data use in any privacy notices in clear, plain language under GDPR anyway, but to go beyond that, and offer customers fair presentation of both risks and customer benefits, will not only be a point-of-sales benefit, but potentially improve digital literacy in customers too.
The morning discussion touched quite often on pay-for-privacy models. While product makers may see this as offering a good thing, I strove to bring discussion back to first principles.
Privacy is a human right. There can be no ethical model of discrimination based on any non-consensual invasion of privacy. Privacy is not something I should pay to have. You should not design products that reduce my rights. GDPR requires privacy-by-design and data protection by default. Now is that chance for IoT manufacturers to lead that shift towards higher standards.
We also need a new ethics thinking on acceptable fair use. It won’t change overnight, and perfect may be the enemy of better. But it’s not a battle that companies should think consumers have lost. Human rights and information security should not be on the battlefield at all in the war to win customer loyalty. Now is the time to do better, to be better, demand better for us and in particular, for our children.
Privacy will be a genuine market differentiator
If manufacturers do not want to change their approach to exploiting customer data, they are unlikely to be seen to have changed.
Today feelings that people in US and Europe reflect in surveys are loss of empowerment, feeling helpless, and feeling used. That will shift to shock, resentment, and any change curve will predict, anger.
“The poll of just over two thousand British adults carried out by Ipsos MORI found that the media, internet services such as social media and search engines and telecommunication companies were the least trusted to use personal data appropriately.” [2014, Data trust deficit with lessons for policymakers, Royal Statistical Society]
In the British student population, one 2015 survey of university applicants in England, found of 37,000 who responded, the vast majority of UCAS applicants agree that sharing personal data can benefit them and support public benefit research into university admissions, but they want to stay firmly in control. 90% of respondents said they wanted to be asked for their consent before their personal data is provided outside of the admissions service.
In 2010, a multi method model of research with young people aged 14-18, by the Royal Society of Engineering, found that, “despite their openness to social networking, the Facebook generation have real concerns about the privacy of their medical records.” [2010, Privacy and Prejudice, RAE, Wellcome]
When people use privacy settings on Facebook set to maximum, they believe they get privacy, and understand little of what that means behind the scenes.
Are there tools designed by others, like Projects by If licenses, and ways this can be done, that you’re not even considering yet?
What if you don’t do it?
“But do you feel like you have privacy today?” I was asked the question in the afternoon. How do people feel today, and does it matter? Companies exploiting consumer data and getting caught doing things the public don’t expect with their data, has repeatedly damaged consumer trust. Data breaches and lack of information security have damaged consumer trust. Both cause reputational harm. Damage to reputation can harm customer loyalty. Damage to customer loyalty costs sales, profit and upsets the Board.
Where overreach into our living rooms has raised awareness of invasive data collection, we are yet to be able to see and understand the invasion of privacy into our thinking and nudge behaviour, into our perception of the world on social media, the effects on decision making that data analytics is enabling as data shows companies ‘how we think’, granting companies access to human minds in the abstract, even before Facebook is there in the flesh.
Governments want to see how we think too, and is thought crime really that far away using database labels of ‘domestic extremists’ for activists and anti-fracking campaigners, or the growing weight of policy makers attention given to predpol, predictive analytics, the [formerly] Cabinet Office Nudge Unit, Google DeepMind et al?
Had the internet remained decentralized the debate may be different.
I am starting to think of the IoT not as the Internet of Things, but as the Internet of Tracking. If some have their way, it will be the Internet of Thinking.
Considering our centralised Internet of Things model, our personal data from human interactions has become the network infrastructure, and data flows, are controlled by others. Our brains are the new data servers.
In the Internet of Tracking, people become the end nodes, not things.
And it is this where the future users will be so important. Do you understand and plan for factors that will drive push back, and crash of consumer confidence in your products, and take it seriously?
Companies have a choice to act as Empires would – multinationals, joining up even on low levels, disempowering individuals and sucking knowledge and power at the centre. Or they can act as Nation states ensuring citizens keep their sovereignty and control over a selected sense of self.
Look at Brexit. Look at the GE2017. Tell me, what do you see is the direction of travel? Companies can fight it, but will not defeat how people feel. No matter how much they hope ‘nudge’ and predictive analytics might give them this power, the people can take back control.
What might this desire to take-back-control mean for future consumer models? The afternoon discussion whilst intense, reached fairly simplistic concluding statements on privacy. We could have done with at least another hour.
Some in the group were frustrated “we seem to be going backwards” in current approaches to privacy and with GDPR.
But if the current legislation is reactive because companies have misbehaved, how will that be rectified for future? The challenge in the IoT both in terms of security and privacy, AND in terms of public perception and reputation management, is that you are dependent on the behaviours of the network, and those around you. Good and bad. And bad practices by one, can endanger others, in all senses.
If you believe that is going back to reclaim a growing sense of citizens’ rights, rather than accepting companies have the outsourced power to control the rights of others, that may be true.
There was a first principle asked whether any element on privacy was needed at all, if the text was simply to state, that the supplier of this product or service must be General Data Protection Regulation (GDPR) compliant. The GDPR was years in the making after all. Does it matter more in the IoT and in what ways? The room tended, understandably, to talk about it from the company perspective. “We can’t” “won’t” “that would stop us from XYZ.” Privacy would however be better addressed from the personal point of view.
What do people want?
From the company point of view, the language is different and holds clues. Openness, control, and user choice and pay for privacy are not the same thing as the basic human right to be left alone. Afternoon discussion reminded me of the 2014 WAPO article, discussing Mark Zuckerberg’s theory of privacy and a Palo Alto meeting at Facebook:
“Not one person ever uttered the word “privacy” in their responses to us. Instead, they talked about “user control” or “user options” or promoted the “openness of the platform.” It was as if a memo had been circulated that morning instructing them never to use the word “privacy.””
In the afternoon working group on privacy, there was robust discussion whether we had consensus on what privacy even means. Words like autonomy, control, and choice came up a lot. But it was only a beginning. There is opportunity for better. An academic voice raised the concept of sovereignty with which I agreed, but how and where to fit it into wording, which is at once both minimal and applied, and under a scribe who appeared frustrated and wanted a completely different approach from what he heard across the group, meant it was left out.
This group do care about privacy. But I wasn’t convinced that the room cared in the way that the public as a whole does, but rather only as consumers and customers do. But IoT products will affect potentially everyone, even those who do not buy your stuff. Everyone in that room, agreed on one thing. The status quo is not good enough. What we did not agree on, was why, and what was the minimum change needed to make a enough of a difference that matters.
I share the deep concerns of many child rights academics who see the harm that efforts to avoid restrictions Article 8 the GDPR will impose. It is likely to be damaging for children’s right to access information, be discriminatory according to parents’ prejudices or socio-economic status, and ‘cheating’ – requiring secrecy rather than privacy, in attempts to hide or work round the stringent system.
In ‘The Class’ the research showed, ” teachers and young people have a lot invested in keeping their spheres of interest and identity separate, under their autonomous control, and away from the scrutiny of each other.” [2016, Livingstone and Sefton-Green, p235]
Employers require staff use devices with single sign including web and activity tracking and monitoring software. Employee personal data and employment data are blended. Who owns that data, what rights will employees have to refuse what they see as excessive, and is it manageable given the power imbalance between employer and employee?
What is this doing in the classroom and boardroom for stress, anxiety, performance and system and social avoidance strategies?
A desire for convenience creates shortcuts, and these are often met using systems that require a sign-on through the platforms giants: Google, Facebook, Twitter, et al. But we are kept in the dark how by using these platforms, that gives access to them, and the companies, to see how our online and offline activity is all joined up.
Any illusion of privacy we maintain, we discussed, is not choice or control if based on ignorance, and backlash against companies lack of efforts to ensure disclosure and understanding is growing.
“The lack of accountability isn’t just troubling from a philosophical perspective. It’s dangerous in a political climate where people are pushing back at the very idea of globalization. There’s no industry more globalized than tech, and no industry more vulnerable to a potential backlash.”
If your connected *thing* requires registration, why does it? How about a commitment to not forcing one of these registration methods or indeed any at all? Social Media Research by Pew Research in 2016 found that 56% of smartphone owners ages 18 to 29 use auto-delete apps, more than four times the share among those 30-49 (13%) and six times the share among those 50 or older (9%).
Does that tell us anything about the demographics of data retention preferences?
In 2012, they suggested social media has changed the public discussion about managing “privacy” online. When asked, people say that privacy is important to them; when observed, people’s actions seem to suggest otherwise.
Does that tell us anything about how well companies communicate to consumers how their data is used and what rights they have?
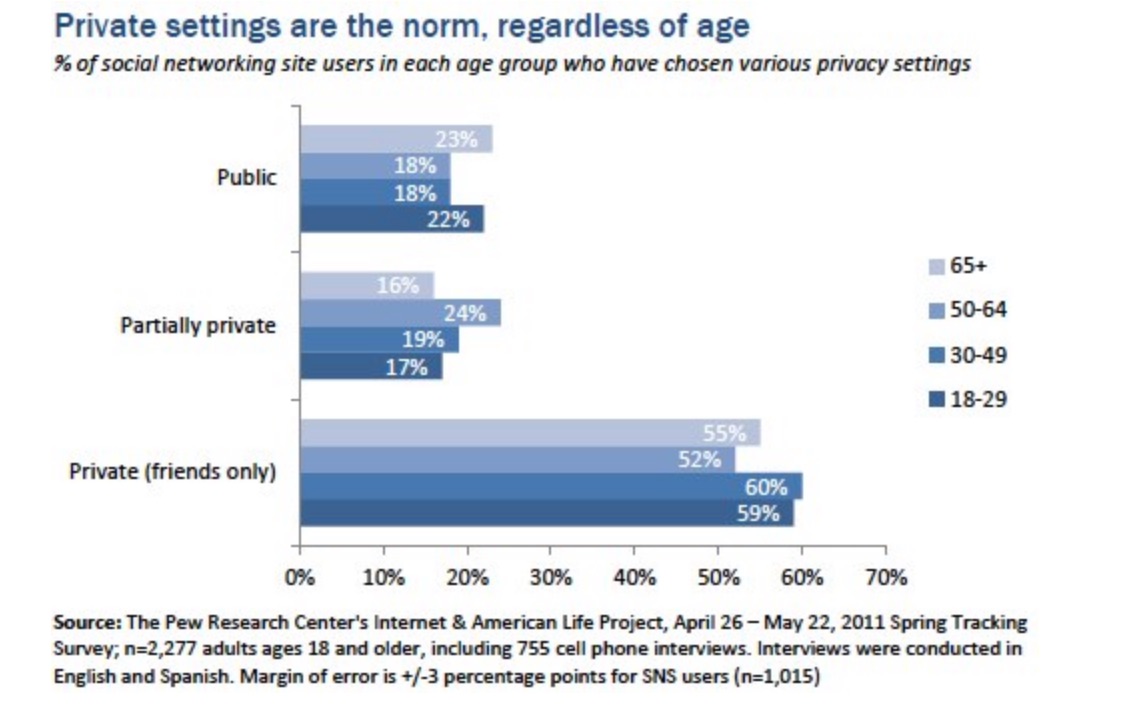
There is also data with strong indications about how women act to protect their privacy more but when it comes to basic privacy settings, users of all ages are equally likely to choose a private, semi-private or public setting for their profile. There are no significant variations across age groups in the US sample.
Now think about why that matters for the IoT? I wonder who makes the bulk of purchasing decsions about household white goods for example and has Bosch factored that into their smart-fridges-only decision?
Do you *need* to know who the user is? Can the smart user choose to stay anonymous at all?
The day’s morning challenge was to attend more than one interesting discussion happening at the same time. As invariably happens, the session notes and quotes are always out of context and can’t possibly capture everything, no matter how amazing the volunteer (with thanks!). But here are some of the discussion points from the session on the body and health devices, the home, and privacy. It also included a discussion on racial discrimination, algorithmic bias, and the reasons why care.data failed patients and failed as a programme. We had lengthy discussion on ethics and privacy: smart meters, objections to models of price discrimination, and why pay-for-privacy harms the poor by design.
Smart meter data can track the use of unique appliances inside a person’s home and intimate patterns of behaviour. Information about our consumption of power, what and when every day, reveals personal details about everyday lives, our interactions with others, and personal habits.
Why should company convenience come above the consumer’s? Why should government powers, trump personal rights?
Smart meter is among the knowledge that government is exploiting, without consent, to discover a whole range of issues, including ensuring that “Troubled Families are identified”. Knowing how dodgy some of the school behaviour data might be, that helps define who is “troubled” there is a real question here, is this sound data science? How are errors identified? What about privacy? It’s not your policy, but if it is your product, what are your responsibilities?
If companies do not respect children’s rights, you’d better shape up to be GDPR compliant
For children and young people, more vulnerable to nudge, and while developing their sense of self can involve forming, and questioning their identity, these influences need oversight or be avoided.
In terms of GDPR, providers are going to pay particular attention to Article 8 ‘information society services’ and parental consent, Article 17 on profiling, and rights to restriction of processing (19) right to erasure in recital 65 and rights to portability. (20) However, they may need to simply reassess their exploitation of children and young people’s personal data and behavioural data. Article 57 requires special attention to be paid by regulators to activities specifically targeted at children, as ‘vulnerable natural persons’ of recital 75.
Human Rights, regulations and conventions overlap in similar principles that demand respect for a child, and right to be let alone:
(a) The development of the child ‘s personality, talents and mental and physical abilities to their fullest potential;
(b) The development of respect for human rights and fundamental freedoms, and for the principles enshrined in the Charter of the United Nations.
A weakness of the GDPR is that it allows derogation on age and will create inequality and inconsistency for children as a result. By comparison Article one of the Convention on the Rights of the Child (CRC) defines who is to be considered a “child” for the purposes of the CRC, and states that: “For the purposes of the present Convention, a child means every human being below the age of eighteen years unless, under the law applicable to the child, majority is attained earlier.”<
Article two of the CRC says that States Parties shall respect and ensure the rights set forth in the present Convention to each child within their jurisdiction without discrimination of any kind.
CRC Article 16 says that no child shall be subjected to arbitrary or unlawful interference with his or her honour and reputation.
Article 8 CRC requires respect for the right of the child to preserve his or her identity […] without unlawful interference.
Article 12 CRC demands States Parties shall assure to the child who is capable of forming his or her own views the right to express those views freely in all matters affecting the child, the views of the child being given due weight in accordance with the age and maturity of the child.
That stands in potential conflict with GDPR article 8. There is much on GDPR on derogations by country, and or children, still to be set.
What next for our data in the wild
Hosting the event at the zoo offered added animals, and during a lunch tour we got out on a tour, kindly hosted by a fellow participant. We learned how smart technology was embedded in some of the animal enclosures, and work on temperature sensors with penguins for example. I love tigers, so it was a bonus that we got to see such beautiful and powerful animals up close, if a little sad for their circumstances and as a general basic principle, seeing big animals caged as opposed to in-the-wild.
Freedom is a common desire in all animals. Physical, mental, and freedom from control by others.
I think any manufacturer that underestimates this element of human instinct is ignoring the ‘hidden dragon’ that some think is a myth. Privacy is not dead. It is not extinct, or even unlike the beautiful tigers, endangered. Privacy in the IoT at its most basic, is the right to control our purchasing power. The ultimate people power waiting to be sprung. Truly a crouching tiger. People object to being used and if companies continue to do so without full disclosure, they do so at their peril. Companies seem all-powerful in the battle for privacy, but they are not. Even insurers and data brokers must be fair and lawful, and it is for regulators to ensure that practices meet the law.
When consumers realise our data, our purchasing power has the potential to control, not be controlled, that balance will shift.
“Paper tigers” are superficially powerful but are prone to overextension that leads to sudden collapse. If that happens to the superficially powerful companies that choose unethical and bad practice, as a result of better data privacy and data ethics, then bring it on.
I hope that the IoT mark can champion best practices and make a difference to benefit everyone.
While the companies involved in its design may be interested in consumers, I believe it could be better for everyone, done well. The great thing about the efforts into an #IoTmark is that it is a collective effort to improve the whole ecosystem.
I hope more companies will realise their privacy rights and ethical responsibility in the world to all people, including those interested in just being, those who want to be let alone, and not just those buying.
“If a cat is called a tiger it can easily be dismissed as a paper tiger; the question remains however why one was so scared of the cat in the first place.”
Further reading: Networks of Control – A Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy by Wolfie Christl and Sarah Spiekermann
Time and again, thinking and discussion about these topics is siloed. At the Turing Institute, the Royal Society, the ADRN and EPSRC, in government departments, discussions on data, or within education practitioner, and public circles — we are all having similar discussions about data and ethics, but with little ownership and no goals for future outcomes. If government doesn’t get it, or have time for it, or policy lacks ethics by design, is it in the public interest for private companies, Google et al., to offer a fait accompli?
There is lots of talking about Machine Learning (ML), Artificial Intelligence (AI) and ethics. But what is being done to ensure that real values — respect for rights, human dignity, and autonomy — are built into practice in the public services delivery?
In most recent data policy it is entirely absent. The Digital Economy Act s33 risks enabling, through removal of inter and intra-departmental data protections, an unprecedented expansion of public data transfers, with “untrammelled powers”. Powers without codes of practice, promised over a year ago. That has fall out for the trustworthiness of legislative process, and data practices across public services.
Predictive analytics is growing but poorly understood in the public and public sector.
There is already dependence on computers in aspects of public sector work. Its interactions with others in sensitive situations demands better knowledge of how systems operate and can be wrong. Debt recovery, and social care to take two known examples.
Risk averse, staff appear to choose not to question the outcome of ‘algorithmic decision making’ or do not have the ability to do so. There is reportedly no analysis training for practitioners, to understand the basis or bias of conclusions. This has the potential that instead of making us more informed, decision-making by machine makes us humans less clever.
What does it do to professionals, if they feel therefore less empowered? When is that a good thing if it overrides discriminatory human decisions? How can we tell the difference and balance these risks if we don’t understand or feel able to challenge them?
In education, what is it doing to children whose attainment is profiled, predicted, and acted on to target extra or less focus from school staff, who have no ML training and without informed consent of pupils or parents?
If authorities use data in ways the public do not expect, such as to ID homes of multiple occupancy without informed consent, they will fail the future to deliver uses for good. The ‘public interest’, ‘user need,’ and ethics can come into conflict according to your point of view. The public and data protection law and ethics object to harms from use of data. This type of application has potential to be mind-blowingly invasive and reveal all sorts of other findings.
Widely informed thinking must be made into meaningful public policy for the greatest public good
Our politicians are caught up in the General Election and buried in Brexit.
Meanwhile, the commercial companies taking AI first rights to capitalise on existing commercial advantage could potentially strip public assets, use up our personal data and public trust, and leave the public with little public good. We are already used by global data players, and by machine-based learning companies, without our knowledge or consent. That knowledge can be used to profit business models, that pay little tax into the public purse.
There are valid macro economic arguments about whether private spend and investment are preferable compared with a state’s ability to do the same. But these companies make more than enough to do it all. Does it signal a failure to a commitment to the wider community; not paying just amounts of taxes, is it a red flag to a company’s commitment to public good?
What that public good should look like, depends on who is invited to participate in the room, and not to tick boxes, but to think and to build.
The Royal Society’s Report on AI and Machine Learning published on April 25, showed a working group of 14 participants, including two Google DeepMind representatives, one from Amazon, private equity investors, and academics from cognitive science and genetics backgrounds.
If we are going to form objective policies the inputs that form the basis for them must be informed, but must also be well balanced, and be seen to be balanced. Not as an add on, but be in the same room.
As Natasha Lomas in TechCrunch noted, “Public opinion is understandably a big preoccupation for the report authors — unsurprisingly so, given that a technology that potentially erodes people’s privacy and impacts their jobs risks being drastically unpopular.”
“The report also calls on researchers to consider the wider impact of their work and to receive training in recognising the ethical implications.”
What are those ethical implications? Who decides which matter most? How do we eliminate recognised discriminatory bias? What should data be used for and AI be working on at all? Who is it going to benefit? What questions are we not asking? Why are young people left out of this debate?
Who decides what the public should or should not know?
AI and ML depend on data. Data is often talked about as a panacea to problems of better working together. But data alone does not make people better informed. In the same way that they fail, if they don’t feel it is their job to pick up the fax. A fundamental building block of our future public and private prosperity is understanding data and how we, and the AI, interact. What is data telling us and how do we interpret it, and know it is accurate?
How and where will we start to educate young people about data and ML, if not about their own and use by government and commercial companies?
The whole of Chapter 5 in the report is very good as a starting point for policy makers who have not yet engaged in the area. Privacy while summed up too short in conclusions, is scattered throughout.
Blind spots remain, however.
Over willingness to accommodate existing big private players as their expertise leads design, development and a desire to ‘re-write regulation’.
Slowness to react to needed regulation in the public sector (caught up in Brexit) while commercial drivers and technology change forge ahead
‘How do we develop technology that benefits everyone’ must not only think UK, but global South, especially in the bias in how AI is being to taught, and broad socio-economic barriers in application
Predictive analytics and professional application = unwillingness to question the computer result. In children’s social care this is already having a damaging upturn in the family courts (S31)
Data and technology knowledge and ethics training, must be embedded across the public sector, not only post grad students in machine learning.
Young people are left out of discussions which, after all, are about their future. [They might have some of the best ideas, we miss at our peril.]
There is no time to waste
Children and young people have the most to lose while their education, skills, jobs market, economy, culture, care, and society goes through a series of gradual but seismic shift in purpose, culture, and acceptance before finding new norms post-Brexit. They will also gain the most if the foundations are right. One of these must be getting age verification right in GDPR, not allowing it to enable a massive data grab of child-parent privacy.
Although the RS Report considers young people in the context of a future workforce who need skills training, they are otherwise left out of this report.
“The next curriculum reform needs to consider the educational needs of young people through the lens of the implications of machine learning and associated technologies for the future of work.”
Yes it does, but it must give young people and the implications of ML broader consideration for their future, than classroom or workplace.
We are not yet talking about the effects of teaching technology to learn, and its effect on public services and interactions with the public. Questions that Sam Smith asked in Shadow of the smart machine: Will machine learning end?
At the end of this Information Age we are at a point when machine learning, AI and biotechnology are potentially life enhancing or could have catastrophic effects, if indeed “AI will cause people ‘more pain than happiness” as described by Alibaba’s founder Jack Ma.
The conflict between commercial profit and public good, what commercial companies say they will do and actually do, and fears and assurances over predicted outcomes is personified in the debate between Demis Hassabis, co-founder of DeepMind Technologies, (a London-based machine learning AI startup), and Elon Musk, discussing the perils of artificial intelligence.
Vanity Fair reported that, “Elon Musk began warning about the possibility of A.I. running amok three years ago. It probably hadn’t eased his mind when one of Hassabis’s partners in DeepMind, Shane Legg, stated flatly, “I think human extinction will probably occur, and technology will likely play a part in this.””
Musk was of the opinion that A.I. was probably humanity’s “biggest existential threat.”
We are not yet joining up multi disciplinary and cross sector discussions of threats and opportunities
Jobs, shift in needed skill sets for education, how we think, interact, value each other, accept or reject ownership and power models; and later, from the technology itself. We are not yet talking conversely, the opportunities that the seismic shifts offer in real terms. Or how and why to accept or reject or regulate them.
Where private companies are taking over personal data given in trust to public services, it is reckless for the future of public interest research to assume there is no public objection. How can we object, if not asked? How can children make an informed choice? How will public interest be assured to be put ahead of private profit? If it is intended on balance to be all about altruism from these global giants, then they must be open and accountable.
Private companies are shaping how and where we find machine learning and AI gathering data about our behaviours in our homes and public spaces.
SPACE10, an innovation hub for IKEA is currently running a survey on how the public perceives and “wants their AI to look, be, and act”, with an eye on building AI into their products, for us to bring flat-pack into our houses.
As the surveillance technology built into the Things in our homes attached to the Internet becomes more integral to daily life, authorities are now using it to gather evidence in investigations; from mobile phones, laptops, social media, smart speakers, and games. The IoT so far seems less about the benefits of collaboration, and all about the behavioural data it collects and uses to target us to sell us more things. Our behaviours tell much more than how we act. They show how we think inside the private space of our minds.
Do you want Google to know how you think and have control over that? The companies of the world that have access to massive amounts of data, and are using that data to now teach AI how to ‘think’. What is AI learning? And how much should the State see or know about how you think, or try to predict it?
Who cares, wins?
It is not overstated to say society and future public good of public services, depends on getting any co-dependencies right. As I wrote in the time of care.data, the economic value of data, personal rights and the public interest are not opposed to one another, but have synergies and co-dependency. One player getting it wrong, can create harm for all. Government must start to care about this, beyond the side effects of saving political embarrassment.
Without joining up all aspects, we cannot limit harms and make the most of benefits. There is nuance and unknowns. There is opaque decision making and secrecy, packaged in the wording of commercial sensitivity and behind it, people who can be brilliant but at the end of the day, are also, human, with all our strengths and weaknesses.
And we can get this right, if data practices get better, with joined up efforts.
Our future society, as our present, is based on webs of trust, on our social networks on- and offline, that enable business, our education, our cultural, and our interactions. Children must trust they will not be used by systems. We must build trustworthy systems that enable future digital integrity.
The immediate harm that comes from blind trust in AI companies is not their AI, but the hidden powers that commercial companies have to nudge public and policy maker behaviours and acceptance, towards private gain. Their ability and opportunity to influence regulation and future direction outweighs most others. But lack of transparency about their profit motives is concerning. Carefully staged public engagement is not real engagement but a fig leaf to show ‘the public say yes’.
The unwillingness by Google DeepMind, when asked at their public engagement event, to discuss their past use of NHS patient data, or the profit model plan or their terms of NHS deals with London hospitals, should be a warning that these questions need answers and accountability urgently.
Companies that have already extracted and benefited from personal data in the public sector, have already made private profit. They and their machines have learned for their future business product development.
A transparent accountable future for all players, private and public, using public data is a necessary requirement for both the public good and private profit. It is not acceptable for departments to hide their practices, just as it is unacceptable if firms refuse algorithmic transparency.
“Rebooting antitrust for the information age will not be easy. It will entail new risks: more data sharing, for instance, could threaten privacy. But if governments don’t want a data economy dominated by a few giants, they will need to act soon.” [The Economist, May 6]
If the State creates a single data source of truth, or private Giant tech thinks it can side-step regulation and gets it wrong, their practices screw up public trust. It harms public interest research, and with it our future public good.
But will they care?
If we care, then across public and private sectors, we must cherish shared values and better collaboration. Embed ethical human values into development, design and policy. Ensure transparency of where, how, who and why my personal data has gone.
We must ensure that as the future becomes “smarter”, we educate ourselves and our children to stay intelligent about how we use data and AI.
We must start today, knowing how we are used by both machines, and man.
Notes and thoughts from Full Fact’s event at Newspeak House in London on 27/3 to discuss fake news, the misinformation ecosystem, and how best to respond. The recording is here. The contributions and questions part of the evening began from 55.55.
What is fake news? Are there solutions?
1. Clickbait: celebrity pull to draw online site visitors towards traffic to an advertising model – kill the business model
2. Mischief makers: Deceptive with hostile intent – bots, trolls, with an agenda
3. Incorrectly held views: ‘vaccinations cause autism’ despite the evidence to the contrary. How can facts reach people who only believe what they want to believe?
Why does it matter? The scrutiny of people in power matters – to politicians, charities, think tanks – as well as the public.
It is fundamental to remember that we do in general believe that the public has a sense of discernment, however there is also a disconnect between an objective truth and some people’s perception of reality. Can this conflict be resolved? Is it necessary to do so? If yes, when is it necessary to do so and who decides that?
There is a role for independent tracing of unreliable information, its sources and its distribution patterns and identifying who continues to circulate fake news even when asked to desist.
Transparency about these processes is in the public interest.
Overall, there is too little public understanding of how technology and online tools affect behaviours and decision-making.
The Role of Media in Society
How do you define the media?
How can average news consumers distinguish between self-made and distributed content compared with established news sources?
What is the role of media in a democracy?
What is the mainstream media?
Does the media really represent what I want to understand? > Does the media play a role in failure of democracy if news is not representative of all views? > see Brexit, see Trump
What are news values and do we have common press ethics?
New problems in the current press model:
Failure of the traditional media organisations in fact checking; part of the problem is that the credible media is under incredible pressure to compete to gain advertising money share.
Journalism is under resourced. Verification skills are lacking and tools can be time consuming. Techniques like reverse image search, and verification take effort.
Press releases with numbers can be less easily scrutinised so how do we ensure there is not misinformation through poor journalism?
What about confirmation bias and reinforcement?
What about friends’ behaviours? Can and should we try to break these links if we are not getting a fair picture? The Facebook representative was keen to push responsibility for the bubble entirely to users’ choices. Is this fair given the opacity of the model?
Have we cracked the bubble of self-reinforcing stories being the only stories that mutual friends see?
Can we crack the echo chamber?
How do we start to change behaviours? Can we? Should we?
The risk is that if people start to feel nothing is trustworthy, we trust nothing. This harms relations between citizens and state, organisations and consumers, professionals and public and between us all. Community is built on relationships. Relationships are built on trust. Trust is fundamental to a functioning society and economy.
Is it game over?
Will Moy assured the audience that there is no need to descend into blind panic and there is still discernment among the public.
Then, it was asked, is perhaps part of the problem that the Internet is incapable in its current construct to keep this problem at bay? Is part of the solution re-architecturing and re-engineering the web?
What about algorithms? Search engines start with word frequency and neutral decisions but are now much more nuanced and complex. We really must see how systems decide what is published. Search engines provide but also restrict our access to facts and ‘no one gets past page 2 of search results’. Lack of algorithmic transparency is an issue, but will not be solved due to commercial sensitivities.
Fake news creation can be lucrative. Mangement models that rely on user moderation or comments to give balance can be gamed.
Are there appropriate responses to the grey area between trolling and deliberate deception through fake news that is damaging? In what context and background? Are all communities treated equally?
The question came from the audience whether the panel thought regulation would come from the select committee inquiry. The general response was that it was unlikely.
What are the solutions?
The questions I came away thinking about went unanswered, because I am not sure there are solutions as long as the current news model exists and is funded in the current way by current players.
I believe one of the things that permits fake news is the growing imbalance of money between the big global news distributors and independent and public interest news sources.
This loss of balance, reduces our ability to decide for ourselves what we believe and what matters to us.
The monetisation of news through its packaging in between advertising has surely contaminated the news content itself.
Think of a Facebook promoted post – you can personalise your audience to a set of very narrow and selective characteristics. The bubble that receives that news is already likely to be connected by similar interest pages and friends and the story becomes self reinforcing, showing up in friends’ timelines.
A modern online newsroom moves content on the webpage around according to what is getting the most views and trending topics in a list encourage the viewers to see what other people are reading, and again, are self reinforcing.
There is also a lack of transparency of power. Where we see a range of choices from which we may choose to digest a range of news, we often fail to see one conglomerate funder which manages them all.
The discussion didn’t address at all the fundamental shift in “what is news” which has taken place over the last twenty years. In part, I believe the responsibility for the credibility level of fake news in viewers lies with 24/7 news channels. They have shifted the balance of content from factual bulletins, to discussion and opinion. Now while the news channel is seen as a source of ‘news’ much of the time, the content is not factual, but opinion, and often that means the promotion and discussion of the opinions of their paymaster.
Most simply, how should I answer the question that my ten year old asks – how do I know if something on the Internet is true or not?
Can we really say it is up to the public to each take on this role and where do we fit the needs of the vulnerable or children into that?
Is the term fake news the wrong approach and something to move away from? Can we move solutions away from target-fixation ‘stop fake news’ which is impossible online, but towards what the problems are that fake news cause?
Interference in democracy. Interference in purchasing power. Interference in decision making. Interference in our emotions.
These interferences with our autonomy is not something that the web is responsible for, but the people behind the platforms must be accountable for how their technology works.
In the mean time, what can we do?
“if we ever want the spread of fake news to stop we have to take responsibility for calling out those who share fake news (real fake news, not just things that feel wrong), and start doing a bit of basic fact-checking ourselves.” [IB Times, Eliot Higgins is the founder of Bellingcat]
Not everyone has the time or capacity to each do that. As long as today’s imbalance of money and power exists, truly independent organisations like Bellingcat and FullFact have an untold value.
The billed Google and Twitter speakers were absent because they were invited to a meeting with the Home Secretary on 28/3. Speakers were Will Moy, Director of FullFact, Jenni Sargent Managing Director of firstdraftnews, Richard Allan, Facebook EMEA Policy Director and the event was chaired by Bill Thompson.
The Higher Education and Research Bill sucks in personal data to the centre, as well as power. It creates an authoritarian panopticon of the people within the higher education and further education systems. Section 1, parts 72-74 creates risks but offers no safeguards.
Applicants and students’ personal data is being shifted into a top-down management model, at the same time as the horizontal safeguards for its distribution are to be scrapped.
Through deregulation and the building of a centralised framework, these bills will weaken the purposes for which personal data are collected, and weaken existing requirements on consent to which the data may be used at national level. Without amendments, every student who enters this system will find their personal data used at the discretion of any future Secretary of State for Education without safeguards or oversight, and forever. Goodbye privacy.
But in addition and separately, the Bill will permit data to be used at the discretion of the Secretary of State, which waters down and removes nuances of consent for what data may or may not be used today when applicants sign up to UCAS.
Applicants today are told in the privacy policy they can consent separately to sharing their data with the Student Loans company for example. This Bill will remove that right when it permits all Applicant data to be used by the State.
This removal of today’s consent process denies all students their rights to decide who may use their personal data beyond the purposes for which they permit its sharing.
And it explicitly overrides the express wishes registered by the 28,000 applicants, 66% of respondents to a 2015 UCAS survey, who said as an example, that they should be asked before any data was provided to third parties for student loan applications (or even that their data should never be provided for this).
Not only can the future purposes be changed without limitation, by definition, when combined with other legislation, namely the Digital Economy Bill that is in the Lords at the same time right now, this shift will pass personal data together with DWP and in connection with HMRC data expressly to the Student Loans Company.
In just this one example, the Higher Education and Research Bill is being used as a man in the middle. But it will enable all data for broad purposes, and if those expand in future, we’ll never know.
This change, far from making more data available to public interest research, shifts the balance of power between state and citizen and undermines the very fabric of its source of knowledge; the creation and collection of personal data.
Further, a number of amendments have been proposed in the Lords to clause 9 (the transparency duty) which raise more detailed privacy issues for all prospective students, concerns UCAS share.
Why this lack of privacy by design is damaging
This shift takes away our control, and gives it to the State at the very time when ‘take back control’ is in vogue. These bills are building a foundation for a data Brexit.
And without future limitation, what might be imposed is unknown.
This shortsightedness will ultimately cause damage to data integrity and the damage won’t come in education data from the Higher Education Bill alone. The Higher Education and Research Bill is just one of three bills sweeping through Parliament right now which build a cumulative anti-privacy storm together, in what is labelled overtly as data sharing legislation or is hidden in tucked away clauses.
Unlike the Higher Education and Research Bill, it may not fundamentally changing how the State gathers information on further education, but it has the potential to do so on use.
The change is a generalisation of purposes. Currently, subsection 1 of section 54 refers to “purposes of the exercise of any of the functions of the Secretary of State under Part 4 of the Apprenticeships, Skills, Children and Learning Act 2009”.
Therefore, the government argues, “it would not hold good in circumstances where certain further education functions were transferred from the Secretary of State to some combined authorities in England, which is due to happen in 2018.”<
This is why clause 38 will amend that wording to “purposes connected with further education”.
Whatever the details of the reason, the purposes are broader.
Again, combined with the Digital Economy Bill’s open ended purposes, it means the Secretary of State could agree to pass these data on to every other government department, a range of public bodies, and some private organisations.
These loose purposes, without future restrictions, definitions of third parties it could be given to or why, or clear need to consult the public or parliament on future scope changes, is a repeat of similar legislative changes which have resulted in poor data practices using school pupil data in England age 2-19 since 2000.
Policy makers should consider whether the intent of these three bills is to give out identifiable, individual level, confidential data of young people under 18, for commercial use without their consent? Or to journalists and charities access? Should it mean unfettered access by government departments and agencies such as police and Home Office Removals Casework teams without any transparent register of access, any oversight, or accountability?
These are today’s uses by third-parties of school children’s individual, identifiable and sensitive data from the National Pupil Database.
Uses of data not as statistics, but named individuals for interventions in individual lives.
Hoping that the data transfers to the Home Office won’t result in the deportation of thousands we would not predict today, may be naive.
Under the new open wording, the Secretary of State for Education might even decide to sell the nation’s entire Technical and Further Education student data to Trump University for the purposes of their ‘research’ to target marketing at UK students or institutions that may be potential US post-grad applicants. The Secretary of State will have the data simply because she “may require [it] for purposes connected with further education.”
And to think US buyers or others would not be interested is too late.
In 2015 Stanford University made a request of the National Pupil Database for both academic staff and students’ data. It was rejected. We know this only from the third party release register. Without any duty to publish requests, approved users or purposes of data release, where is the oversight for use of these other datasets?
If these are not the intended purposes of these three bills, if there should be any limitation on purposes of use and future scope change, then safeguards and oversight need built into the face of the bills to ensure data privacy is protected and avoid repeating the same again.
Hoping that the decision is always going to be, ‘they wouldn’t approve a request like that’ is not enough to protect millions of students privacy.
The three bills are a perfect privacy storm
As other Europeans seek to strengthen the fundamental rights of their citizens to take back control of their personal data under the GDPR coming into force in May 2018, the UK government is pre-emptively undermining ours in these three bills.
Young people, and data dependent institutions, are asking for solutions to show what personal data is held where, and used by whom, for what purposes. That buys in the benefit message that builds trust showing what you said you’d do with my data, is what you did with my data. [1] [2]
Reality is that in post-truth politics it seems anything goes, on both sides of the Pond. So how will we trust what our data is used for?
2015-16 advice from the cross party Science and Technology Committee suggested data privacy is unsatisfactory, “to be left unaddressed by Government and without a clear public-policy position set out“. We hear the need for data privacy debated about use of consumer data, social media, and on using age verification. It’s necessary to secure the public trust needed for long term public benefit and for economic value derived from data to be achieved.
But the British government seems intent on shortsighted legislation which does entirely the opposite for its own use: in the Higher Education Bill, the Technical and Further Education Bill and in the Digital Economy Bill.
These bills share what Baroness Chakrabarti said of the Higher Education Bill in its Lords second reading on the 6th December, “quite an achievement for a policy to combine both unnecessary authoritarianism with dangerous degrees of deregulation.”
Unchecked these Bills create the conditions needed for catastrophic failure of public trust. They shift ever more personal data away from personal control, into the centralised control of the Secretary of State for unclear purposes and use by undefined third parties. They jeopardise the collection and integrity of public administrative data.
To future-proof the immediate integrity of student personal data collection and use, the DfE reputation, and public and professional trust in DfE political leadership, action must be taken on safeguards and oversight, and should consider:
Transparency register: a public record of access, purposes, and benefits to be achieved from use
Subject Access Requests: Providing the public ways to access copies of their own data
Consent procedures should be strengthened for collection and cannot say one thing, and do another
Ability to withdraw consent from secondary purposes should be built in by design, looking to GDPR from 2018
Clarification of the legislative purpose of intended current use by the Secretary of State and its boundaries shoud be clear
Future purpose and scope change limitations should require consultation – data collected today must not used quite differently tomorrow without scrutiny and ability to opt out (i.e. population wide registries of religion, ethnicity, disability)
Review or sunset clause
If the legislation in these three bills pass without amendment, the potential damage to privacy will be lasting.
Schools Minister Nick Gibb responded on July 25th 2016: ”
“These new data items will provide valuable statistical information on the characteristics of these groups of children […] “The data will be collected solely for internal Departmental use for the analytical, statistical and research purposes described above. There are currently no plans to share the data with other government Departments”
[2] December 15, publication of MOU between the Home Office Casework Removals Team and the DfE, reveals “the previous agreement “did state that DfE would provide nationality information to the Home Office”, but that this was changed “following discussions” between the two departments.” http://schoolsweek.co.uk/dfe-had-agreement-to-share-pupil-nationality-data-with-home-office/
The agreement was changed on 7th October 2016 to not pass nationality data over. It makes no mention of not using the data within the DfE for the same purposes.
Mike Loukides drew similarities between the current status of AI and children’s learning in an article I read this week.
The children I know are always curious to know where they are going, how long will it take, and how they will know when they get there. They ask others for guidance often.
Loukides wrote that if you look carefully at how humans learn, you see surprisingly little unsupervised learning.
If unsupervised learning is a prerequisite for general intelligence, but not the substance, what should we be looking for, he asked. It made me wonder is it also true that general intelligence is a prerequisite for unsupervised learning? And if so, what level of learning must AI achieve before it is capable of recursive self-improvement? What is AI being encouraged to look for as it learns, what is it learning as it looks?
What is AI looking for and how will it know when it gets there?
Loukides says he can imagine a toddler learning some rudiments of counting and addition on his or her own, but can’t imagine a child developing any sort of higher mathematics without a teacher.
I suggest a different starting point. I think children develop on their own, given a foundation. And if the foundation is accompanied by a purpose — to understand why they should learn to count, and why they should want to — and if they have the inspiration, incentive and assets they’ll soon go off on their own, and outstrip your level of knowledge. That may or may not be with a teacher depending on what is available, cost, and how far they get compared with what they want to achieve.
It’s hard to learn something from scratch by yourself if you have no boundaries to set knowledge within and search for more, or to know when to stop when you have found it.
You’ve only to start an online course, get stuck, and try to find the solution through a search engine to know how hard it can be to find the answer if you don’t know what you’re looking for. You can’t type in search terms if you don’t know the right words to describe the problem.
I described this recently to a fellow codebar-goer, more experienced than me, and she pointed out something much better to me. Don’t search for the solution or describe what you’re trying to do, ask the search engine to find others with the same error message.
In effect she said, your search is wrong. Google knows the answer, but can’t tell you what you want to know, if you don’t ask it in the way it expects.
So what will AI expect from people and will it care if we dont know how to interrelate? How does AI best serve humankind and defined by whose point-of-view? Will AI serve only those who think most closely in AI style steps and language? How will it serve those who don’t know how to talk about, or with it? AI won’t care if we don’t.
If as Loukides says, we humans are good at learning something and then applying that knowledge in a completely different area, it’s worth us thinking about how we are transferring our knowledge today to AI and how it learns from that. Not only what does AI learn in content and context, but what does it learn about learning?
His comparison of a toddler learning from parents — who in effect are ‘tagging’ objects through repetition of words while looking at images in a picture book — made me wonder how we will teach AI the benefit of learning? What incentive will it have to progress?
“the biggest project facing AI isn’t making the learning process faster and more efficient. It’s moving from machines that solve one problem very well (such as playing Go or generating imitation Rembrandts) to machines that are flexible and can solve many unrelated problems well, even problems they’ve never seen before.”
Is the skill to enable “transfer learning” what will matter most?
For AI to become truly useful, we need better as a global society to understand *where* it might best interface with our daily lives, and most importantly *why*. And consider *who* is teaching and AI and who is being left out in the crowdsourcing of AI’s teaching.
Who is teaching AI what it needs to know?
The natural user interfaces for people to interact with today’s more common virtual assistants (Amazon’s Alexa, Apple’s Siri and Viv, Microsoft and Cortana) are not just providing information to the user, but through its use, those systems are learning. I wonder what percentage of today’s population is using these assistants, how representative are they, and what our AI assistants are being taught through their use? Tay was a swift lesson learned for Microsoft.
In helping shape what AI learns, what range of language it will use to develop its reference words and knowledge, society co-shapes what AI’s purpose will be — and for AI providers to know what’s the point of selling it. So will this technology serve everyone?
Are providers counter-balancing what AI is currently learning from crowdsourcing, if the crowd is not representative of society?
So far we can only teach machines to make decisions based on what we already know, and what we can tell it to decide quickly against pre-known references using lots of data. Will your next image captcha, teach AI to separate the sloth from the pain-au-chocolat?
One of the task items for machine processing is better searches. Measurable goal driven tasks have boundaries, but who sets them? When does a computer know, if it’s found enough to make a decision. If the balance of material about the Holocaust on the web for example, were written by Holocaust deniers will AI know who is right? How will AI know what is trusted and by whose measure?
What will matter most is surely not going to be how to optimise knowledge transfer from human to AI — that is the baseline knowledge of supervised learning — and it won’t even be for AI to know when to use its skill set in one place and when to apply it elsewhere in a different context; so-called learning transfer, as Mike Loukides says. But rather, will AI reach the point where it cares?
Will AI ever care what it should know and where to stop or when it knows enough on any given subject?
How will it know or care if what it learns is true?
If in the best interests of advancing technology or through inaction we do not limit its boundaries, what oversight is there of its implications?
Online limits will limit what we can reach in Thinking and Learning
If you look carefully at how humans learn online, I think rather than seeing surprisingly little unsupervised learning, you see a lot of unsupervised questioning. It is often in the questioning that is done in private we discover, and through discovery we learn. Often valuable discoveries are made; whether in science, in maths, or important truths are found where there is a need to challenge the status quo. Imagine if Galileo had given up.
The freedom to think freely and to challenge authority, is vital to protect, and one reason why I and others are concerned about the compulsory web monitoring starting on September 5th in all schools in England, and its potential chilling effect. Some are concerned who might have access to these monitoring results today or in future, if stored could they be opened to employers or academic institutions?
If you tell children do not use these search terms and do not be curious about *this* subject without repercussions, it is censorship. I find the idea bad enough for children, but for us as adults its scary.
As Frankie Boyle wrote last November, we need to consider what our internet history is:
“The legislation seems to view it as a list of actions, but it’s not. It’s a document that shows what we’re thinking about.”
Children think and act in ways that they may not as an adult. People also think and act differently in private and in public. It’s concerning that our private online activity will become visible to the State in the IP Bill — whether photographs that captured momentary actions in social media platforms without the possibility to erase them, or trails of transitive thinking via our web history — and third-parties may make covert judgements and conclusions about us, correctly or not, behind the scenes without transparency, oversight or recourse.
By narrowing our parameters what will we not discover? Not debate? Or not invent? Happy are the clockmakers, and kids who create. Any restriction on freedom to access information, to challenge and question will restrict children’s learning or even their wanting to. It will limit how we can improve our shared knowledge and improve our society as a result. The same is true of adults.
So in teaching AI how to learn, I wonder how the limitations that humans put on its scope — otherwise how would it learn what the developers want — combined with showing it ‘our thinking’ through search terms, and how limitations on that if users self-censor due to surveillance, will shape what AI will help us with in future and will it be the things that could help the most people, the poorest people, or will it be people like those who programme the AI and use search terms and languages it already understands?
Who is accountable for the scope of what we allow AI to do or not? Who is accountable for what AI learns about us, from our behaviour data if it is used without our knowledge?
How far does AI have to go?
The leap for AI will be if and when AI can determine what it doesn’t know, and it sees a need to fill that gap. To do that, AI will need to discover a purpose for its own learning, indeed for its own being, and be able to do so without limitation from the that humans shaped its framework for doing so. How will AI know what it needs to know and why? How will it know, what it knows is right and sources to trust? Against what boundaries will AI decide what it should engage with in its learning, who from and why? Will it care? Why will it care? Will it find meaning in its reason for being? Why am I here?
We assume AI will know better. We need to care, if AI is going to.
How far are we away from a machine that is capable of recursive self-improvement, asks John Naughton in yesterday’s Guardian, referencing work by Yuval Harari suggesting artificial intelligence and genetic enhancements will usher in a world of inequality and powerful elites. As I was finishing this, I read his article, and found myself nodding, as I read the implications of new technology focus too much on technology and too little on society’s role in shaping it.
If the purpose of AI is to improve human lives, who defines improvement and who will that improvement serve? Is there a consensus on the direction AI should and should not take, and how far it should go? What will the global language be to speak AI?
As AI learning progresses, every time AI turns to ask its creators, “Are we there yet?”, how will we know what to say?
image: Stephen Barling flickr.com/photos/cripsyduck (CC BY-NC 2.0)
I caught my first Pokémon and I liked it. Well, OK, someone else handed me a phone and insisted I have a go. Turns out my curve ball is pretty good. Pokémon GO is enabling all sorts of new discoveries.
Discoveries reportedly including a dead man, robbery, picking up new friends, and scrapes and bruises. While players are out hunting anime in augmented reality, enjoying the novelty, and discovering interesting fun facts about their vicinity, Pokémon GO is gathering a lot of data. It’s influencing human activity in ways that other games can only envy, taking in-game interaction to a whole new level.
What I would like to know is what access goes in the other direction?
Google, heavily invested in AI and Machine intelligence research, has “learning systems placed at the core of interactive services in a fast changing and sometimes adversarial environment, combinations of techniques including deep learning and statistical models need to be combined with ideas from control and game theory.”
The app, which is free to download, has raised concerns over suggestions the app could access a user’s entire Google account, including email and passwords. Then it seemed it couldn’t. But Niantic is reported to have made changes to permissions to limit access to basic profile information anyway.
If Niantic gets access to data owned by Google through its use of google log in credentials, does Nantic’s investor, Google’s Alphabet, get the reverse: user data from the Google log in interaction with the app, and if so, what does Google learn through the interaction?
Who gets access to what data and why?
Brian Crecente writes that Apple, Google, Niantic likely making more on Pokémon Go than Nintendo, with 30 percent of revenue from in-app purchases on their online stores.
Next stop is to make money from marketing deals between Niantic and the offline stores used as in-game focal points, gyms and more, according to Bryan Menegus at Gizmodo who reported Redditors had discovered decompiled code in the Android and iOS versions of Pokémon Go earlier this week “that indicated a potential sponsorship deal with global burger chain McDonald’s.”
The logical progressions of this, is that the offline store partners, i.e. McDonald’s and friends, will be making money from players, the people who get led to their shops, restaurants and cafes where players will hang out longer than the Pokéstop, because the human interaction with other humans, the battles between your collected creatures and teamwork, are at the heart of the game. Since you can’t visit gyms until you are level 5 and have chosen a team, players are building up profiles over time and getting social in real life. Location data that may build up patterns about the players.
This evening the two players that I spoke to were already real-life friends on their way home from work (that now takes at least an hour longer every evening) and they’re finding the real-life location facts quite fun, including that thing they pass on the bus every day, and umm, the Scientology centre. Well, more about that later**.
Every player I spotted looking at the phone with that finger flick action gave themselves away with shared wry smiles. All 30 something men. There is possibly something of a legacy in this they said, since the initial Pokémon game released 20 years ago is drawing players who were tweens then.
Since the app is online and open to all, children can play too. What this might mean for them in the offline world, is something the NSPCC picked up on here before the UK launch. Its focus of concern is the physical safety of young players, citing the risk of in-game lures misuse. I am not sure how much of an increased risk this is compared with existing scenarios and if children will be increasingly unsupervised or not. It’s not a totally new concept. Players of all ages must be mindful of where they are playing**. Some stories of people getting together in the small hours of the night has generated some stories which for now are mostly fun. (Go Red Team.) Others are worried about hacking. And it raises all sorts of questions if private and public space is has become a Pokestop.
While the NSPCC includes considerations on the approach to privacy in a recent more general review of apps, it hasn’t yet mentioned the less obvious considerations of privacy and ethics in Pokémon GO. Encouraging anyone, but particularly children, out of their home or protected environments and into commercial settings with the explicit aim of targeting their spending. This is big business.
Privacy in Pokémon GO
I think we are yet to see a really transparent discussion of the broader privacy implications of the game because the combination of multiple privacy policies involved is less than transparent. They are long, they seem complete, but are they meaningful?
We can’t see how they interact.
Google has crowd sourced the collection of real time traffic data via mobile phones. Geolocation data from google maps using GPS data, as well as network provider data seem necessary to display the street data to players. Apparently you can download and use the maps offline since Pokémon GO uses the Google Maps API. Google goes to “great lengths to make sure that imagery is useful, and reflects the world our users explore.” In building a Google virtual reality copy of the real world, how data are also collected and will be used about all of us who live in it, is a little wooly to the public.
U.S. Senator Al Franken is apparently already asking Niantic these questions. He points out that Pokémon GO has indicated it shares de-identified and aggregate data with other third parties for a multitude of purposes but does not describe the purposes for which Pokémon GO would share or sell those data [c].
It’s widely recognised that anonymisation in many cases fails so passing only anonymised data may be reassuring but fail in reality. Stripping out what are considered individual personal identifiers in terms of data protection, can leave individuals with unique characteristics or people profiled as groups.
Opt out he feels is inadequate as a consent model for the personal and geolocational data that the app is collecting and passing to others in the U.S.
While the app provider would I’m sure argue that the UK privacy model respects the European opt in requirement, I would be surprised if many have read it. Privacy policies fail.
Poor practices must be challenged if we are to preserve the integrity of controlling the use of our data and knowledge about ourselves. Being aware of who we have ceded control of marketing to us, or influencing how we might be interacting with our environment, is at least a step towards not blindly giving up control of free choice.
The Pokémon GO permissions “for the purpose of performing services on our behalf“, “third party service providers to work with us to administer and provide the Services” and “also use location information to improve and personalize our Services for you (or your authorized child)” are so broad as they could mean almost anything. They can also be changed without any notice period. It’s therefore pretty meaningless. But it’s the third parties’ connection, data collection in passing, that is completely hidden from players.
If we are ever to use privacy policies as meaningful tools to enable consent, then they must be transparent to show how a chain of permissions between companies connect their services.
Otherwise they are no more than get out of jail free cards for the companies that trade our data behind the scenes, if we were ever to claim for its misuse. Data collectors must improve transparency.
Behavioural tracking and trust
Covert data collection and interaction is not conducive to user trust, whether through a failure to communicate by design or not.
By combining location data and behavioural data, measuring footfall is described as “the holy grail for retailers and landlords alike” and it is valuable. “Pavement Opportunity” data may be sent anonymously, but if its analysis and storage provides ways to pitch to people, even if not knowing who they are individually, or to groups of people, it is discriminatory and potentially invisibly predatory. The pedestrian, or the player, Jo Public, is a commercial opportunity.
Pokémon GO has potential to connect the opportunity for profit makers with our pockets like never before. But they’re not alone.
Whether footfall outside the shops or packaged as a game that gets us inside them, public interest researchers and commercial companies alike both risk losing our trust if we feel used as pieces in a game that we didn’t knowingly sign up to. It’s creepy.
For children the ethical implications are even greater.
There are obligations to meet higher legal and ethical standards when processing children’s data and presenting them marketing. Parental consent requirements fail children for a range of reasons.
So far, the UK has said it will implement the EU GDPR. Clear and affirmative consent is needed. Parental consent will be required for the processing of personal data of children under age 16. EU Member States may lower the age requiring parental consent to 13, so what that will mean for children here in the UK is unknown.
The ethics of product placement and marketing rules to children of all ages go out the window however, when the whole game or programme is one long animated advert. On children’s television and YouTube, content producers have turned brand product placement into programmes: My Little Pony, Barbie, Playmobil and many more.
Alice Webb, Director of BBC Children’s and BBC North, looked at some of the challenges in this as the BBC considers how to deliver content for children whilst adapting to technological advances in this LSE blog and the publication of a new policy brief about families and ‘screen time’, by Alicia Blum-Ross and Sonia Livingstone.
So is this augmented reality any different from other platforms?
Yes because you can’t play the game without accepting the use of the maps and by default some sacrifice of your privacy settings.
Yes because the ethics and implications of of putting kids not simply in front of a screen that pitches products to them, but puts them physically into the place where they can consume products – if the McDonalds story is correct and a taster of what will follow – is huge.
Boundaries between platforms and people
Blum-Ross says, “To young people, the boundaries and distinctions that have traditionally been established between genres, platforms and devices mean nothing; ditto the reasoning behind the watershed system with its roots in decisions about suitability of content. “
She’s right. And if those boundaries and distinctions mean nothing to providers, then we must have that honest conversation with urgency. With our contrived consent, walking and running and driving without coercion, we are being packaged up and delivered right to the door of for-profit firms, paying for the game with our privacy. Smart cities are exploiting street sensors to do the same.
Some stories of how behaviour is affected, are heartbreakingly positive. And I met and chatted with complete strangers who shared the joy of something new and a mutual curiosity of the game. Pokémon GOis clearly a lot of fun. It’s also unclear on much more.
I would like to explicitly understand if Pokémon GO is gift packaging behavioural research by piggybacking on the Google platforms that underpin it, and providing linked data to Google or third parties.
Fishing for frequent Pokémon encourages players to ‘check in’ and keep that behaviour tracking live. 4pm caught a Krabby in the closet at work. 6pm another Krabby. Yup, still at work. 6.32pm Pidgey on the street outside ThatGreenCoffeeShop. Monday to Friday.
The Google privacy policies changed in the last year require ten clicks for opt out, and in part, the download of an add-on. Google has our contacts, calendar events, web searches, health data, has invested in our genetics, and all the ‘Things that make you “you”. They have our history, and are collecting our present. Machine intelligence work on prediction, is the future. For now, perhaps that will be pinging you with a ‘buy one get one free’ voucher at 6.20, or LCD adverts shifting as you drive back home.
Pokémon GO doesn’t have to include what data Google collects in its privacy policy. It’s in Google’s privacy policy. And who really read that when it came out months ago, or knows what it means in combination with new apps and games we connect it with today? Tracking and linking data on geolocation, behavioural patterns, footfall, whose other phones are close by, who we contact, and potentially even our spend from Google wallet.
Have Google and friends of Niantic gotta know it all?
This blog post is also available as an audio file on soundcloud.
Anais Nin, wrote in her 1946 diary of the dangers she saw in the growth of technology to expand our potential for connectivity through machines, but diminish our genuine connectedness as people. She could hardly have been more contemporary for today:
“This is the illusion that might cheat us of being in touch deeply with the one breathing next to us. The dangerous time when mechanical voices, radios, telephone, take the place of human intimacies, and the concept of being in touch with millions brings a greater and greater poverty in intimacy and human vision.” [Extract from volume IV 1944-1947]
Echoes from over 70 years ago, can be heard in the more recent comments of entrepreneur Elon Musk. Both are concerned with simulation, a lack of connection between the perceived, and reality, and the jeopardy this presents for humanity. But both also have a dream. A dream based on the positive potential society has.
How will we use our potential?
Data is the connection we all have between us as humans and what machines and their masters know about us. The values that masters underpin their machine design with, will determine the effect the machines and knowledge they deliver, have on society.
In seeking ever greater personalisation, a wider dragnet of data is putting together ever more detailed pieces of information about an individual person. At the same time data science is becoming ever more impersonal in how we treat people as individuals. We risk losing sight of how we respect and treat the very people whom the work should benefit.
Nin grasped the risk that a wider reach, can mean more superficial depth. Facebook might be a model today for the large circle of friends you might gather, but how few you trust with confidences, with personal knowledge about your own personal life, and the privilege it is when someone chooses to entrust that knowledge to you. Machine data mining increasingly tries to get an understanding of depth, and may also add new layers of meaning through profiling, comparing our characteristics with others in risk stratification.
Data science, research using data, is often talked about as if it is something separate from using information from individual people. Yet it is all about exploiting those confidences.
Today as the reach has grown in what is possible for a few people in institutions to gather about most people in the public, whether in scientific research, or in surveillance of different kinds, we hear experts repeatedly talk of the risk of losing the valuable part, the knowledge, the insights that benefit us as society if we can act upon them.
We might know more, but do we know any better? To use a well known quote from her contemporary, T S Eliot, ‘Where is the wisdom we have lost in knowledge? Where is the knowledge we have lost in information?’
What can humans achieve? We don’t yet know our own limits. What don’t we yet know? We have future priorities we aren’t yet aware of.
To be able to explore the best of what Nin saw as ‘human vision’ and Musk sees in technology, the benefits we have from our connectivity; our collaboration, shared learning; need to be driven with an element of humility, accepting values that shape boundaries of what we should do, while constantly evolving with what we could do.
The essence of this applied risk is that technology could harm you, more than it helps you. How do we avoid this and develop instead the best of what human vision makes possible? Can we also exceed our own expectations of today, to advance in moral progress?
This blog post is also available as an audio file on soundcloud.
What constitutes the public interest must be set in a universally fair and transparent ethics framework if the benefits of research are to be realised – whether in social science, health, education and more – that framework will provide a strategy to getting the pre-requisite success factors right, ensuring research in the public interest is not only fit for the future, but thrives. There has been a climate change in consent. We need to stop talking about barriers that prevent datasharing and start talking about the boundaries within which we can.
What is the purpose for which I provide my personal data?
‘We use math to get you dates’, says OkCupid’s tagline.
That’s the purpose of the site. It’s the reason people log in and create a profile, enter their personal data and post it online for others who are looking for dates to see. The purpose, is to get a date.
When over 68K OkCupid users registered for the site to find dates, they didn’t sign up to have their identifiable data used and published in ‘a very large dataset’ and onwardly re-used by anyone with unregistered access. The users data were extracted “without the express prior consent of the user […].”
Are the registration consent purposes compatible with the purposes to which the researcher put the data should be a simple enough question. Are the research purposes what the person signed up to, or would they be surprised to find out their data were used like this?
Questions the “OkCupid data snatcher”, now self-confessed ‘non-academic’ researcher, thought unimportant to consider.
But it appears in the last month, he has been in good company.
Google DeepMind, and the Royal Free, big players who do know how to handle data and consent well, paid too little attention to the very same question of purposes.
The boundaries of how the users of OkCupid had chosen to reveal information and to whom, have not been respected in this project.
Nor were these boundaries respected by the Royal Free London trust that gave out patient data for use by Google DeepMind with changing explanations, without clear purposes or permission.
The respectful ethical boundaries of consent to purposes, disregarding autonomy, have indisputably broken down, whether by commercial org, public body, or lone ‘researcher’.
Research purposes
The crux of data access decisions is purposes. What question is the research to address – what is the purpose for which the data will be used? The intent by Kirkegaard was to test:
“the relationship of cognitive ability to religious beliefs and political interest/participation…”
In this case the question appears intended rather a test of the data, not the data opened up to answer the test. While methodological studies matter, given the care and attention [or self-stated lack thereof] given to its extraction and any attempt to be representative and fair, it would appear this is not the point of this study either.
The data doesn’t include profiles identified as heterosexual male, because ‘the scraper was’. It is also unknown how many users hide their profiles, “so the 99.7% figure [identifying as binary male or female] should be cautiously interpreted.”
“Furthermore, due to the way we sampled the data from the site, it is not even representative of the users on the site, because users who answered more questions are overrepresented.” [sic]
The paper goes on to say photos were not gathered because they would have taken up a lot of storage space and could be done in a future scraping, and
“other data were not collected because we forgot to include them in the scraper.”
The data are knowingly of poor quality, inaccurate and incomplete. The project cannot be repeated as ‘the scraping tool no longer works’. There is an unclear ethical or peer review process, and the research purpose is at best unclear. We can certainly give someone the benefit of the doubt and say intent appears to have been entirely benevolent. It’s not clear what the intent was. I think it is clearly misplaced and foolish, but not malevolent.
The trouble is, it’s not enough to say, “don’t be evil.” These actions have consequences.
When the researcher asserts in his paper that, “the lack of data sharing probably slows down the progress of science immensely because other researchers would use the data if they could,” in part he is right.
Google and the Royal Free have tried more eloquently to say the same thing. It’s not research, it’s direct care, in effect, ignore that people are no longer our patients and we’re using historical data without re-consent. We know what we’re doing, we’re the good guys.
However the principles are the same, whether it’s a lone project or global giant. And they’re both wildly wrong as well. More people must take this on board. It’s the reason the public interest needs the Dame Fiona Caldicott review published sooner rather than later.
Just because there is a boundary to data sharing in place, does not mean it is a barrier to be ignored or overcome. Like the registration step to the OkCupid site, consent and the right to opt out of medical research in England and Wales is there for a reason.
We’re desperate to build public trust in UK research right now. So to assert that the lack of data sharing probably slows down the progress of science is misplaced, when it is getting ‘sharing’ wrong, that caused the lack of trust in the first place and harms research.
A climate change in consent
There has been a climate change in public attitude to consent since care.data, clouded by the smoke and mirrors of state surveillance. It cannot be ignored. The EUGDPR supports it. Researchers may not like change, but there needs to be an according adjustment in expectations and practice.
Without change, there will be no change. Public trust is low. As technology advances and if we continue to see commercial companies get this wrong, we will continue to see public trust falter unless broken things get fixed. Change is possible for the better. But it has to come from companies, institutions, and people within them.
Like climate change, you may deny it if you choose to. But some things are inevitable and unavoidably true.
There is strong support for public interest research but that is not to be taken for granted. Public bodies should defend research from being sunk by commercial misappropriation if they want to future-proof public interest research.
The purpose for which the people gave consent are the boundaries within which you have permission to use data, that gives you freedom within its limits, to use the data. Purposes and consent are not barriers to be overcome.
If research is to win back public trust developing a future proofed, robust ethical framework for data science must be a priority today.
This case study and indeed the Google DeepMind recent episode by contrast demonstrate the urgency with which working out what common expectations and oversight of applied ethics in research, who gets to decide what is ‘in the public interest’ and data science public engagement must be made a priority, in the UK and beyond.
Boundaries in the best interest of the subject and the user
Society needs research in the public interest. We need good decisions made on what will be funded and what will not be. What will influence public policy and where needs attention for change.
To do this ethically, we all need to agree what is fair use of personal data, when is it closed and when is it open, what is direct and what are secondary uses, and how advances in technology are used when they present both opportunities for benefit or risks to harm to individuals, to society and to research as a whole.
The potential benefits of research are potentially being compromised for the sake of arrogance, greed, or misjudgement, no matter intent. Those benefits cannot come at any cost, or disregard public concern, or the price will be trust in all research itself.
In discussing this with social science and medical researchers, I realise not everyone agrees. For some, using deidentified data in trusted third party settings poses such a low privacy risk, that they feel the public should have no say in whether their data are used in research as long it’s ‘in the public interest’.
For the DeepMind researchers and Royal Free, they were confident even using identifiable data, this is the “right” thing to do, without consent.
For the Cabinet Office datasharing consultation, the parts that will open up national registries, share identifiable data more widely and with commercial companies, they are convinced it is all the “right” thing to do, without consent.
How can researchers, society and government understand what is good ethics of data science, as technology permits ever more invasive or covert data mining and the current approach is desperately outdated?
Who decides where those boundaries lie?
“It’s research Jim, but not as we know it.” This is one aspect of data use that ethical reviewers will need to deal with, as we advance the debate on data science in the UK. Whether independents or commercial organisations. Google said their work was not research. Is‘OkCupid’ research?
If this research and data publication proves anything at all, and can offer lessons to learn from, it is perhaps these three things:
Researchers and ethics committees need to adjust to the climate change of public consent. Purposes must be respected in research particularly when sharing sensitive, identifiable data, and there should be no assumptions made that differ from the original purposes when users give consent.
Data ethics and laws are desperately behind data science technology. Governments, institutions, civil, and all society needs to reach a common vision and leadership how to manage these challenges. Who defines these boundaries that matter?
How do we move forward towards better use of data?
Our data and technology are taking on a life of their own, in space which is another frontier, and in time, as data gathered in the past might be used for quite different purposes today.
The public are being left behind in the game-changing decisions made by those who deem they know best about the world we want to live in. We need a say in what shape society wants that to take, particularly for our children as it is their future we are deciding now.
How about an ethical framework for datasharing that supports a transparent public interest, which tries to build a little kinder, less discriminating, more just world, where hope is stronger than fear?
Working with people, with consent, with public support and transparent oversight shouldn’t be too much to ask. Perhaps it is naive, but I believe that with an independent ethical driver behind good decision-making, we could get closer to datasharing like that.
Purposes and consent are not barriers to be overcome. Within these, shaped by a strong ethical framework, good data sharing practices can tackle some of the real challenges that hinder ‘good use of data’: training, understanding data protection law, communications, accountability and intra-organisational trust. More data sharing alone won’t fix these structural weaknesses in current UK datasharing which are our really tough barriers to good practice.
How our public data will be used in the public interest will not be a destination or have a well defined happy ending, but it is a long term process which needs to be consensual and there needs to be a clear path to setting out together and achieving collaborative solutions.
While we are all different, I believe that society shares for the most part, commonalities in what we accept as good, and fair, and what we believe is important. The family sitting next to me have just counted out their money and bought an ice cream to share, and the staff gave them two. The little girl is beaming. It seems that even when things are difficult, there is always hope things can be better. And there is always love.