It’s a privilege to have a letter published in the FT as I do today, and thanks to the editors for all their work in doing so.
I’m a bit sorry that it lost the punchline which was supposed to bring a touch of AI humour about pirates and their stochastic parrots. And its rather key point was cut that,
“Nothing in current European laws, including Convention 108 for the UK, prevents companies developing AI lawfully.”
So for the record, and since it’s (£), my agreed edited version was:
“The multi-signatory open letter advertisement, paid for by Meta, entitled “Europe needs regulatory certainty on AI” (September 19) was fittingly published on International Talk Like a Pirate Day.
It seems the signatories believe they cannot do business in Europe without “pillaging” more of our data and are calling for new law.
Since many companies lobbied against the General Data Protection Regulation or for the EU AI Act to be weaker, or that the Council of Europe’s AI regulation should not apply to them, perhaps what they really want is approval to turn our data into their products without our permission.
Nothing in current European laws, including Convention 108 for the UK, prevents companies developing AI lawfully. If companies want more consistent enforcement action, I suggest Data Protection Authorities comply and act urgently to protect us from any pirates out there, and their greedy stochastic parrots. “
Prior to print they asked to cut out a middle paragraph too.
“In the same week, LinkedIn sneakily switched on a ‘use me for AI development’ feature for UK users without telling us (paused the next day); Larry Ellison suggested at Oracle’s Financial Analyst Meeting that more AI should usher in an era of mass citizen surveillance, and our Department for Education has announced it will allow third parties to exploit school children’s assessment data for AI product building, and can’t rule out it will include personal data.”
It is in fact the cumulative effect around the recent flurry of AI activities by various parties, state and commercial, that deserves greater attention rather than being only about this Meta-led complaint. Who is grabbing what data and what infrastructure contracts and creating what state dependencies and strengths to what end game? While some present the “AI race” as China or India versus the EU or the US to become AI “super powers”, is what “Silicon Valley” offers, their way is the only way, a better offer?
It’s not in fact, “Big Tech” I’m concerned about, but the arrogance of so many companies that in the middle of regulatory scrutiny would align themselves with one that would rather put out PR that omits the fact they are under it, instead only calling for the law to be changed, and frankly misleading the public by suggesting it is all for our own good than talk about how this serves their own interests.
Who do they think they are to dictate what new laws must look like when they seem simply unwilling to stick to those we have?
The Meta-led ad called for “harmonisation enshrined in regulatory frameworks like the GDPR” and I absolutely agree. The DPAs need to stand tall and stand up to OpenAI and friends (ever dwindling in number so it seems) and reassert the basic, fundamental principles of data protection laws from the GDPR to Convention 108 to protect fundamental human rights. Our laws should do so whether companies like them or not. After all, it is often abuse of data rights by companies, and states, that populations need protection from.
The Netherlands DPA is right to say scraping is almost always unlawful. A legitimate interest cannot be simply plucked from thin air by anyone who is neither an existing data controller nor processor and has no prior relationship to the data subjects who have no reasonable expectation of their re-use of data online that was not posted for the purposes that the scraper has grabbed it and without any informed processing and offer of an opt out. Instead the only possible basis for this kind of brand new controller should be consent. Having to break the law, hardly screams ‘innovation’.
Regulators do not exist to pander to wheedling, but to independently uphold the law in a democratic society in order to protect people, not prioritise the creation of products:
Lawfulness, fairness and transparency.
Purpose limitation.
Data minimisation.
Accuracy.
Storage limitation.
Integrity and confidentiality (security)
and
Accountability.
In my view, it is the lack of dissausive enforcement as part of checks-and-balances on big power like this, regardless of where it resides, that poses one of the biggest data-related threats to humanity.
Not AI, nor being “left out” of being used to build it for their profit.
Recent conversations and the passage of the Data Protection and Digital Information Bill in parliament, have made me think once again about what the future vision for UK children’s data could be.
Some argue that processing and governance should be akin to a health model, first do no harm, professional standards, training, ISO lifecycle oversight, audits and governance bodies to approve exceptional releases and re-use.
Education data is health and body data
Children’s personal data in the educational context is remarkably often health data directly (social care, injury, accident, self harm, mental health) or indirectly (mood and emotion or eating patterns).
Children’s data in education is increasingly bodily data. An AI education company CEO was even reported to have considered, “bone-mapping software to track pupils’ emotions” linking a child’s bodily data and data of the mind. For a report written by Pippa King and myself in 2021, The State of Biometrics 2022: A Review of Policy and Practice in UK Education, we mapped the emerging prevalence of biometrics in educational settings. Published on the ten-year anniversary of the Protection of Freedoms Act 2012, we challenged the presumption that the data protection law is complied with well, or is effective enough alone in the protection of children’s data or digital rights.
We mustn’t forget, when talking about data in education, children do not go to school in order to produce data or to have their lives recorded, monitored or profiled through analytics. It’s not the purpose of their activity. They go to school to exercise their right in law to receive education, that data production is a by-product of the activity they are doing.
Education data as a by product of the process
Thinking of these together as children’s lives in by-products used by others, reminded me of the Alder Hey scandal published over twenty years ago, but going back decades. In particular, the inquiry considered the huge store of body parts and residual human tissue of dead children accumulated between 1988 to 1995.
“It studied the obligation to establish ‘lack of objection’ in the event of a request to retain organs and tissue taken at a Coroner’s post-mortem for medical education and research.” (2001)
Thinking about the parallels of children’s personal data produced and extracted in education as a by-product, and organ and tissue waste a by-product of routine medical procedures in the living, highlights several lessons that we could be drawing today about digital processing of children’s lives in data and child/parental rights.
Digital bodies of the dead less protected than their physical parts
It also exposes gaps between the actual scenario today that the bodily tissue and the bodily data about deceased children could be being treated differently, since the data protection regime only applies to the living. We should really be forward looking and include rights here for all that go beyond the living “natural persons”, because our data does, and that may affect those who we leave behind. It is insufficient for researchers and others who wish to use data without restriction to object, because this merely pushes off the problem, increasing the risk of public rejection of ‘hidden’ plans later. (see DDM second reading briefing on recital 27, p 30/32),
What could we learn from handling body parts for the digital body?
In the children’s organ and tissue scandal, management failed to inform or provide suitable advice and support necessary to families.
Recommendations were made for change on consent to post-mortem examinations of children, and a new approach to consent and an NHS hospital post-mortem consent form for children and all residual tissue were adopted sector-wide.
The retention and the destruction of genetic material is considered in the parental consent process required for any testing that continues to use the bodily material from the child. In the Alder Hey debate this was about deceased children, but similar processes are in place now for obtaining parental consent to research re-use and retention for waste or ‘surplus’ tissue that comes from everyday operations on the living.
The DPDI Bill will consider the data of the dead for the first time
To date it only covers the data of or related to the living or “natural persons” and it is ironic that the rest of the Bill does the polar opposite, not about living and dead, but by redefining both personal data and research purposes it takes what is today personal data ‘in scope’ of data protection law and places it out of scope and beyond its governance due to exemptions, or changes in controller responsibility over time. Meaning a whole lot of data about children and the rest of us) will not be covered by DP law at all. (Yes, those are bad things in the Bill).
Separately, the new law as drafted, will also create a divergence from its generally accepted scope, and will start to bring data into scope the ‘personal data’ of the dead.
Perhaps as a result of limited parliamentary time, the DPDI Bill (see col. 939) is being used to include amendments on, “Retention of information by providers of internet services in connection with death of child,” to amend the Online Safety Act 2023to enable OFCOM to give internet service providers a notice requiring them to retain information in connection with an investigation by a coroner (or, in Scotland, procurator fiscal) into the death of a child suspected to have taken their own life. The new clause also creates related offences.”
While primarily for the purposes of formal investigation into the role of social media in children’s suicide, and directions from Ofcom to social media companies to retain information for the period of one year beginning with the date of the notice, it highlights the difficulty of dealing with data after the death of a loved one.
This problem is perhaps no less acute where a child or adult has left no ‘digital handover’ via a legacy contact eg at Apple you can assign someone to be this person in the event of your own death from any cause. But what happens if your relation has not set this up and has been the holder of the digital key to your entire family photo history stored on a company’s cloud? Is this a question of data protection, or digital identity management, or of physical product ownership?
Harvesting children’s digital bodies is not what people want
In the current digital landscape personal data can often be seen as a commodity, a product to mine, extract and exploit and pass around to others. More of an ownership and IP question and the broadly U.S. approach. Data collection is excessive in “Big Data” mountains and “data lakes”, described just like the EU food surpluses of the 1970s. Extraction and use without effective controls creates toxic waste, is polluting and met with resistance. This environment is not sustainable and not what young people want. Enforcement of the data protection principles of purpose limitation and data minimisation should be helping here, but young people don’t see it.
When personal data is considered as ‘of the body’ or bodily residue, data as part of our life, the resulting view was that data is something that needs protecting. That need is generally held to be true, and represented in European human rights-based data laws and regulation. A key aim of protecting data is to protect the person.
In a workshop for that report preparation, teenagers expressed unease that data about them being ‘harvested’ to exploit as human capital and find their rights are not adequately enabled or respected. They find data can be used to replace conversation with them, and mean they are misrepresented by it, and at the same time there is a paradox that a piece of data can be your ‘life story’ and single source of truth advocating on your behalf.
Parental and children’s rights are grafted together and need recognised processes that respect this, as managed in health
Children’s competency and parental rights are grafted together in many areas of a child’s life and death, so why not by default in the digital environment? What additional mechanisms in a process are needed where both views carry legal weight? What are the specific challenges that need extra attention in data protection law due to the characteristics of data that can be about more than one person, be controlled by and not only be about the child, and parental rights?
What might we learn for the regulation of practice of a child’s digital footprint from how health manages residual tissue processing? Who is involved, what are the steps of the process and how is it communicated onwardly accompanying data flows around a system?
Where data protection rules do not apply, certain activities may still constitute an interference with Article 8 of the European Convention on Human Rights, which protects the right to private and family life. (WP 29 Opinion 4/2007 on the concept of personal data p24).
Undoubtedly the datafied child is an inseparable ‘data double’ of the child. Data users about children, who do so without their permission, without informing them or their families, without giving children and parents the tools to exercise their rights to have a say and control their digital footprint in life and in death, might soon find themselves being treated in the same way as accountable individuals in the Alder Hey scandal were, many years after the events took place.
Minor edits and section sub-headings added on 18/12 for clarity plus a reference to the WP29 opinion 04/2007 on personal data.
Ray-Ban (EssilorLuxxotica) is selling glasses with ‘Facebook View’. The questions have already been asked whether they can be lawful in Europe, including in the UK, in particular in regards to enabling the processing of children’s personal data without consent.
the legal basis on which Facebook processes personal data;
the measures in place to protect people recorded by the glasses, children in particular,
questions of anonymisation of the data collected; and
the voice assistant connected to the microphone in the glasses.
While the first questions in Europe may be bound to data protection law and privacy, there are also questions of why Facebook has gone ahead despite Google Glass that was removed from the market in 2013. You can see a pair displayed in a surveillance exhibit at the Victoria and Albert museum (September 2021).
“We can’t wait to see the world from your perspective“, says Ray-ban Chief Wearables Officer Rocco Basilico in the promotional video together with Mark Zuckerberg. I bet. But not as much as Facebook.
With cameras and microphones built-in, up to around 30 videos or 500 photos can be stored on the glasses, and shared with Facebook companion app. While the teensy light on a corner is supposed to be an indicator that recording is in progress, the glasses look much like any other and indistinguishable in the Ray-ban range. You can even buy them as prescription glasses, which intrigues me as to how that recording looks on playback, or shared via the companion apps.
“We believe this is an important step on the road to developing the ultimate augmented reality glasses“, says Mark Zuckerberg.(05:46)
The company needs a lawful basis to be able to process the data it receives for those purposes. It determines those purposes, and is therefore a data controller for that processing.
In the supplemental policy the company says that “Facebook View is intended solely for users who are 13 or older.” Data Protection law does not care about the age of the product user, but it does regulate under what basis a child’s data may be processed and that may be the user, setting up an account. It is also concerned about the data of the children who are recorded. By recognising the legal limitations on who can be an account owner, it has a bit of a self-own here on what the law says on children’s data.
Personal privacy may have weak protection in data protection laws that offer the wearer exemptions for domestic** or journalistic purposes, but neither the user nor the company can avoid the fact that processing video and audio recordings may be without (a) adequately informing people whose data is processed or (b) appropriate purpose limitation for any processing that Facebook the company performs, across all of its front end apps and platforms or back-end processes.
I’ve asked Facebook how I would, as a parent or child, be able to get a wearer to destroy a child’s images and video or voice recorded in a public space, to which I did not consent. How would I get to see that content once held by Facebook, or request its processing be restricted by the company, or user, or the data destroyed?
Testing the Facebook ‘contact our DPO’ process as if I were a regular user, fails. It has sent me round the houses via automated forms.
Facebook is clearly wrong here on privacy grounds but if you can afford the best in the world on privacy law, why would you go ahead anyway? Might they believe after nearly twenty years of privacy invasive practice and a booming bottom line, that there is no risk to reputation, no risk to their business model, and no real risk to the company from regulation?
It’s an interesting partnership since Ray-Ban has no history in understanding privacy. Facebook has a well known controversial one. Reputational risk shared, will not be reputational risk halved. And EssilorLuxottica has a share price to consider. I wonder if they carried out any due diligence risk assessment for their investors?
Destroy the data, destroy the knowledge gained, and remove it from any product development to date. All “Affected Work Product.”
Otherwise any penalty Facebook will get from this debacle, will be just the cost of doing business to have bought itself a very nice training dataset for its AR product development.
Ray-Ban of course, will take all the reputational hit if found enabling strangers to take covert video of our kids. No one expects any better from Facebook. After all, we all know, Facebook takes your privacy, seriously.
Reference: Rynes: On why your ring video doorbell may make you a controller under GDPR.
The news is full of the exam Regulator Ofqual right now, since yesterday’s A-Level results came out. In the outcry over the clear algorithmic injustice and inexplicable data-driven results, the data regulator, the Information Commissioner (ICO) remains silent.**
I have been told the Regulators worked together from early on in the process. So did this collaboration help or hinder the thousands of students and children whose rights the Regulators are supposed to work to protect?
I have my doubts, and here is why.
My child’s named national school records
On April 29, 2015 I wrote to the Department for Education (DfE) to ask for a copy of the data that they held about my eldest child in the National Pupil Database (NPD). A so-called Subject Access Request. The DfE responded on 12 May 2015 and refused, claiming an exemption, section 33(4) of the Data Protection Act 1998. In effect saying it was a research-only, not operational database.
Despite being a parent of three children in state education in England, there was no clear information available to me what the government held in this database about my children. Building on what others in civil society had done before, I began research into what data was held. From where it was sourced and how often it was collected. Who the DfE gave the data to. For what purposes. How long it was kept. And I discovered a growing database of over 20 million individuals, of identifying and sensitive personal data, that is given away to commercial companies, charities, think tanks and press without suppression of small numbers and is never destroyed.
My children’s confidential records that I entrusted to school, and much more information they create that I never see, is given away for commercial purposes and I don’t get told which companies have it, why, or have any control over it? What about my Right to Object? I had imagined a school would only share statistics with third parties without parents’ knowledge or being asked. Well that’s nothing compared with what the Department does with it all next.
My 2015 complaint to the ICO
On October 6, 2015 I made a complaint to the Information Commissioner’s Office (the ICO). Admittedly, I was more naïve and less well informed than I am today, but the facts were clear.
Their response in April 2016, was to accept the DfE position, “at the stage at which this data forms part of its evidence base for certain purposes, it has been anonymised, aggregated and is statistical in nature. Therefore, for the purposes of the DPA, at the stage at which the DfE use NPD data for such purposes, it no longer constitutes personal data in any event.”
The ICO was “satisfied that the DfE met the criteria needed to rely on the exemption contained at section 33(4) of the DPA” and was justified in not fulfilling my request.
And “in relation to your concerns about the NPD and the adequacy of the privacy notice provided by the DfE, in broad terms, we consider it likely that this complies with the relevant data protection principles of the DPA.”
The ICO claimed “the processing does not cause any substantial damage or distress to individuals and that any results of the research/statistics are not made available in a form which identifies data subjects.”
The ICO kept its eyes wide shut
In secret in July 2015, the DfE had started to supply the Home Office with the matched personal details of children from the NPD, including home address. The Home Office requested this for purposes including to further the Hostile Environment. (15.1.2) which I only discovered in detail one year to the day after my ICO complaint, on October 6, 2016. The rest is public.
The ICO made no public statement despite widespread media coverage throughout 2016 and legal action on the expansion of the data, and intended use of children’s nationality and country-of-birth.
Identifying and sensitive not aggregated and statistical
In 2015 there was no Data Protection Impact Assessment. The Department had done zero audits of data users after sending them identifying pupil data. There was no ethics process or paperwork.
Is the ICO a help or hindrance to protect children and young people’s data rights?
Five years ago the ICO told me the named records in the national pupil database was not personal data. Five years on, my legal team and I await a final regulatory response from the ICO that I hope will protect the human rights of my children, the millions currently in education in England whose data are actively collected, the millions aged 18-37 affected whose data were collected 1996-2012 but who don’t know, and those to come.
It has come at significant personal and legal costs and I welcome any support. It must be fixed. The question is whether the information rights Regulator is a help or hindrance?
If the ICO is working with organisations that have broken the law, or that plan dubious or unethical data processing, why is the Regulator collaborating to enable processing and showing them how to smooth off the edges rather than preventing harm and protecting rights? Can the ICO be both a friend and independent enforcer?
Why does it decline to take up complaints on behalf of parents that similarly affect millions of children in the UK and worldwide about companies that claim to use AI on their website but tell the ICO it’s just computing really. Or why has it given a green light on the reuse of religion and ethnicity from schools without consent, and tells the organisation they can later process it to make it anonymous, and keep all the personal data indefinitely?
I am angry at their inaction, but not as angry as thousands of children and their parents who know they have been let down by data-led decisions this month, that to them are inexplicable.
Thousands of children who are caught up in the algorithmic A-Level debacle and will be in next week’s GCSE processes believe they have been unfairly treated through the use of their personal data and have no clear route of redress. Where is the voice of the Regulator? What harm should they have prevented but didn’t through inaction?
What is the point of all the press and posturing on an Age Appropriate Code of Practice which goes beyond the scope of data protection, if the ICO cannot or will not enforce on its core remit or support the public it is supposed to serve?
Update: This post was published at midday on Friday Aust 14. In the late afternoon the ICO did post a short statement on the A-levels crisis, and also wrote to me regarding one of these cases via email.
In August 2019, the Swedish DPA fined Skellefteå Municipality, Secondary Education Board 200 000 SEK (approximately 20 000 euros) pursuant to the General Data Protection Regulation (EU) 2016/679 for using facial recognition technology to monitor the attendance of school children.
This facial recognition technology trial, compared images from camera surveillance with pre-registered images of the face of each child, and processed first and last name.
In the preamble, the decision recognised that the General Data Protection Regulation does not contain any derogations for pilot or trial activities.
In summary, the Authority concluded that by using facial recognition via camera to monitor school children’s attendance, the Secondary Education Board (Gymnasienämnden) in the municipality of Skellefteå (Skellefteå kommun) processed personal data that was unnecessary, excessively invasive, and unlawful; with regard to
Article 5 of the General Data Protection Regulation by processing personal data in a manner that is more intrusive than necessary and encompasses more personal data than is necessary for the specified purpose (monitoring of attendance)
Article 9 processing special category personal data (biometric data) without having a valid derogation from the prohibition on the processing of special categories of personal data,
and
Articles 35 and 36 by failing to fulfil the requirements for an impact assessment and failing to carry out prior consultation with the Swedish Data Protection Authority.
Consent
Perhaps the most significant part of the decision is the first officially documented recognition in education data processing under GDPR, that consent fails, even though explicit guardians’ consent was requested and it was possible to opt out. It recognised that this was about processing the personal data of children in a disempowered relationship and environment.
It makes the assessment that consent was not freely given. It is widely recognised that consent cannot be a tick box exercise, and that any choice must be informed. However, little attention has yet been given in GDPR circles, to the power imbalance of relationships, especially for children.
The decision recognised that the relationship that exists between the data subject and the controller, namely the balance of power, is significant in assessing whether a genuine choice exists, and whether or not it can be freely given without detriment. The scope for voluntary consent within the public sphere is limited:
“As regards the school sector, it is clear that the students are in a position of dependence with respect to the school …”
The Education Board had said that consent was the basis for the processing of the facial recognition in attendance monitoring.
With the Data Protection Authority’s assessment that the consent was invalid, the lawful basis for processing fell away.
The importance of necessity
The basis for processing was consent 6(1)(a), not 6(1)(e) ‘necessary for the performance of a task carried out in the public interest or in the exercise of official authority vested in the controller’ so as to process special category [sensitive] personal data.
However the same test of necessity, was also important in this case. Recital 39 of GDPR requires that personal data should be processed only if the purpose of the processing could not reasonably be fulfilled by other means.
The Swedish Data Protection Authority recognised and noted that, while there is a legal basis for administering student attendance at school, there is no explicit legal basis for performing the task through the processing of special categories of personal data or in any other manner which entails a greater invasion of privacy — put simply, taking the register via facial recognition did not meet the data protection test of being necessary and proportionate. There are less privacy invasive alternatives available, and on balance, the rights of the individual outweigh those of the data processor.
While some additional considerations were made for local Swedish data protection law, (the Data Protection Act (prop. 2017/18:105 Ny dataskyddslag)) even those exceptional provisions were not intended to be applied routinely to everyday tasks.
Considering rights by design
The decision refers to the document provided by the school board, Skellefteå kommun – Framtidens klassrum (Skelleftå municipality – The classroom of the future). In the appendix (p. 5), “it noted one advantage of facial recognition is that it is easy to register a large group such as a class in bulk. The disadvantages mentioned include that it is a technically advanced solution which requires a relatively large number of images of each individual, that the camera must have a free line of sight to all students who are present, and that any headdress/shawls may cause the identification process to fail.”
The Board did not submit a prior consultation for data protection impact assessment to the Authority under Article 36. The Authority considered that a number of factors indicated that the processing operations posed a high risk to the rights and freedoms of the individuals concerned but that these were inadequately addressed, and failed to assess the proportionality of the processing in relation to its purposes.
For example, the processing operations involved
a) the use of new technology,
b) special categories of personal data,
c) children,
d) and a power imbalance between the parties.
As the risk assessment submitted by the Board did not demonstrate an assessment of relevant risks to the rights and freedoms of the data subjects [and its mitigations], the decision noted that the high risks pursuant to Article 36 had not been reduced.
What’s next for the UK
The Swedish Data Protection Authority identifies some important points in perhaps the first significant GDPR ruling in the education sector so far, and much will apply school data processing in the UK.
What may surprise some, is that this decision was not about the distribution of the data; since the data was stored on a local computer without any internet connection. It was not about security, since the computer was kept in a locked cupboard. It was about the fundamentals of basic data protection and rights to privacy for children in the school environment, under the law.
Processing must meet the tests of necessity. Necessary is not defined by a lay test of convenience.
Processing must be lawful. Consent is rarely going to offer a lawful basis for routine processing in schools, and especially when it comes to the risks to the rights and freedoms of the child when processing biometric data, consent fails to offer satisfactory and adequate lawful grounds for processing, due to the power imbalance.
Data should be accurate, be only the minimum necessary and proportionate, and not respect the fundamental rights of the child.
The Swedish DPA fined Skellefteå Municipality, Secondary Education Board 200 000 SEK (approximately 20 000 euros). According to Article 83 (1) of the General Data Protection Regulation, supervisory authorities must ensure that the imposition of administrative fines is effective, proportionate and dissuasive, and in this case, is designed to end the processing infringements.
The GDPR, as preceding data protection law did, offers a route for data controllers and processors to understand what is lawful, and it demands their accountability to be able to demonstrate they are.
Whether children in the UK will find that it affords them their due protections, now depends on its enforcement like this case.
I’ve been thinking about FAT, and the explainability of decision making.
There may be few decisions about people at scale, today in the public sector, in which computer stored data aren’t used. For some, computers are used to make or help make decisions.
How we understand those decisions in a vital part of the obligation of fairness, in data processing. How I know that *you* have data about me, and are processing it, in order to make a decision that affects me. So there’s an awful lot of good things that come out of that. The staff member does their job with better understanding. The person affected has an opportunity to question and correct if necessary, the inputs to the decision. And one hopes, that the computer support can make many decisions faster, and with more information in useful ways, than the human staff member alone.
But, why then, does it seem so hard to get this understood and processes in place to make the decision making understandable?
And more importantly, why does there seem to be no consistency in how such decision-making is documented, and communicated?
From school progress measures, to PIP and Universal Credit applications, to predictive ‘risk scores’ for identifying gang membership and child abuse. In a world where you need to be computer literate but there may be no computer to help you make an application, the computers behind the scenes are making millions of life changing decisions.
We cannot see them happen, and often don’t see the data that goes into them. From start to finish, it is a hidden process.
The current focus on FAT — fairness, accountability, and transparency of algorithmic systems — often makes accountability for the computer part of the decision-making in the public sector, appear something that has become too hard to solve and needs complex thinking around.
I want conversations to go back to something more simple. Humans taking responsibility for their actions. And to do so, we need better infrastructure for whole process delivery, where it involves decision making, in public services.
Academics, boards, conferences, are all spending time on how to make the impact of the algorithms fair, accountable, and transparent. But in the search for ways to explain legal and ethical models of fairness, and to explain the mathematics and logic behind algorithmic systems and machine learning, we’ve lost sight of why anyone needs to know. Who cares and why?
Rather in the same way that the concept of ethics has become captured and distorted by companies to suit their own agenda, so if anything, the focus on FAT has undermined the concept of whole process audit and responsibility for human choices, decisions, and actions.
The effect of a machine-made decision on those who are included in the system response, — and more rarely those who may be left out of it, or its community effects, — has been singled out for a lot of people’s funding and attention as what matters to understand and audit in the use of data for making safe and just decisions.
It’s right to do so, but not as a stand alone cog in the machine.
The computer and its data processing have been unjustifiably deified. Rather than supporting public sector staff they are disempowered in the process as a whole. It is assumed the computer knows best, and can be used to justify a poor decision — “well, what could I do, the data told me to do it?” is rather like, “it was not my job to pick up the fax from the fax machine.” But that’s not a position we should encourage.
We have become far too accommodating of this automated helplessness.
If society feels a need to take back control, as a country and of our own lives, we also need to see decision makers take back responsibility.
The focus on FAT emphasises the legal and ethical obligations on companies and organisations, to be accountable for what the computer says, and the narrow algorithmic decision(s) in it. But it is rare that an outcome in most things in real life, is the result of a singular decision.
So does FAT fit these systems at all?
Do I qualify for PIP? Can your child meet the criteria needed for additional help at school? Does the system tag your child as part of a ‘Troubled Family’? These outcomes are life affecting in the public sector. It should therefore be made possible to audit *if* and *how* the public sector should offer to change lives as a holistic process.
That means re-looking at if and how we audit that whole end-to-end process > from policy idea, to legislation, through design to delivery.
There are no simple, clean, machine readable results in that.
Yet here again, the current system-process-solution encourages the public sector to use *data* to assess and incentivise the process to measure the process, and award success and failure, packaged into surveys and payment-by-results.
The data driven measurement, assesses data driven processes, that compound the problems of this infinite human-out-of-the-loop.
This clean laser-like focus misses out on the messy complexity of our human lives. And the complexity of public service provision makes it very hard to understand the process of delivery. As long as the end-to-end system remains weighted to self preservation, to minimise financial risk to the institution for example, or to find a targeted number of interventions, people will be treated unfairly.
Through a hyper focus on algorithms and computer-led decision accountability, the tech sector, academics and everyone involved, is complicit in a debate that should be about human failure. We already have algorithms in every decision process. Human and machine-led algorithms. Before we decide if we need a new process of fairness, accountability and transparency, we should know who’s responsible now for the outcomes and failure in any given activity, and ask, ‘Does it really need to change?’
To restore some of the power imbalance to the public on decisions about us made by authorities today, we urgently need public bodies to compile, publish and maintain at very minimum, some of the basic underpinning and auditable infrastructure — the ‘plumbing’ — inside these processes:
a register of data analytics systems used by Local and Central Government, including but not only those where algorithmic decision-making affects individuals.
a register of data sources used in those analytics systems.
a consistently identifiable and searchable taxonomy of the companies and third-parties delivering those analytics systems.
a diagrammatic mapping of core public service delivery activities, to understand the tasks, roles, and responsibilities within the process. It would benefit government at all levels to be able to see themselves where decision points sit, understand flows of data and cash, and see where which law supports the task, and accountability sits.
Why? Because without knowing what is being used at scale, how and by whom, we are poorly informed and stay helpless. It allows for enormous and often unseen risks without adequate checks and balances — like named records with the sexual orientation data of almost 3.2 million people, and religious belief data on 3.7 million sitting in multiple distributed databases — and with the massive potential for state-wide abuse by any current or future government. And the responsibility for each part of a process remains unclear.
We need to make increasingly lean systems more fat and stuff them with people power again. Yes we need fairness accountability and transparency. But we need those human qualities to reach across thinking beyond computer code. We need to restore humanity to automated systems and it has to be re-instated across whole processes.
FAT focussed only on computer decisions, is a distraction from auditing failure to deliver systems that work for people. It’s a failure to manage change and of governance, and to be accountable for when things go wrong.
What happens when FAT fails? Who cares and what do they do?
In 2018, ethics became the new fashion in UK data circles.
The launch of the Women Leading in AIprinciples of responsible AI, has prompted me to try and finish and post these thoughts, which have been on my mind for some time. If two parts of 1K is tl:dr for you, then in summary, we need more action on:
Ethics as a route to regulatory avoidance.
Framing AI and data debates as a cost to the Economy.
Reframing the debate around imbalance of risk.
Challenging the unaccountable and the ‘inevitable’.
In 2019, the calls to push aside old wisdoms for new, for everyone to focus on the value-laden words of ‘innovation’ and ‘ethics’, appears an ever louder attempt to reframe regulation and law as barriers to business, asking to cast them aside.
On Wednesday evening, at the launch of the Women Leading in AIprinciples of responsible AI, the chair of the CDEI said in closing, he was keen to hear from companies where, “they were attempting to use AI effectively and encountering difficulties due to regulatory structures.”
Perhaps it’s ingenious PR to make sure that what is in effect self-regulation, right across the business model, looks like it comes imposed from others, from the very bodies set up to fix it.
But as I think about in part 2, is this healthy for UK public policy and the future not of an industry sector, but a whole technology, when it comes to AI?
Framing AI and data debates as a cost to the Economy
Companies, organisations and individuals arguing against regulation are framing the debate as if it would come at a great cost to society and the economy. But we rarely hear, what effect do they expect on their company. What’s the cost/benefit expected for them. It’s disingenuous to have only part of that conversation. In fact the AI debate would be richer were it to be included. If companies think their innovation or profits are at risk from non-use, or regulated use, and there is risk to the national good associated with these products, we should be talking about all of that.
And in addition, we can talk about use and non-use in society. Too often, the whole debate is intangible. Show me real costs, real benefits. Real risk assessments. Real explanations that speak human. Industry should show society what’s in it for them.
You don’t want it to ‘turn out like GM crops’? Then learn their lessons on transparency, trustworthiness, and avoid the hype. And understand sometimes there is simply tech, people do not want.
Reframing the debate around imbalance of risk
And while we often hear about the imbalance of power associated with using AI, we also need to talk about the imbalance of risk.
And where company owners may see no risk from the product they assure is safe, there are intangible risks that need factored in, for example in education where a child’s learning pathway is determined by patterns of behaviour, and how tools shape individualised learning, as well as the model of education.
Companies may change business model, ownership, and move on to other sectors after failure. But with the levels of unfairness already felt in the relationship between the citizen and State — in programmes like Troubled Families, Universal Credit, Policing, and Prevent — where use of algorithms and ever larger datasets is increasing, long term harm from unaccountable failure will grow.
Society needs a rebalance of the system urgently to promote transparent fairness in interactions, including but not only those with new applications of technology.
We must find ways to reframe how this imbalance of risk is assessed, and is distributed between companies and the individual, or between companies and state and society, and enable access to meaningful redress when risks turn into harm.
If we are to do that, we need first to separate truth from hype, public good from self-interest and have a real discussion of risk across the full range from individual, to state, to society at large.
That’s not easy against a non-neutral backdrop and scant sources of unbiased evidence and corporate capture.
Challenging the unaccountable and the ‘inevitable’.
In 2017 the Care Quality Commission reported into online services in the NHS, and found serious concerns of unsafe and ineffective care. They have a cross-regulatory working group.
By contrast, no one appears to oversee that risk and the embedded use of automated tools involved in decision-making or decision support, in children’s services, or education. Areas where AI and cognitive behavioural science and neuroscience are already in use, without ethical approval, without parental knowledge or any transparency.
Meanwhile, as all this goes on, academics many are busy debating fixing algorithmic bias, accountability and its transparency.
Few are challenging the narrative of the ‘inevitability’ of AI.
Julia Powles and Helen Nissenbaum recently wrote that many of these current debates are an academic distraction, removed from reality. It is under appreciated how deeply these tools are already embedded in UK public policy. “Trying to “fix” A.I. distracts from the more urgent questions about the technology. It also denies us the possibility of asking: Should we be building these systems at all?”
Challenging the unaccountable and the ‘inevitable’ is the title of the conclusion of the Women Leading in AI report on principles, and makes me hopeful.
“There is nothing inevitable about how we choose to use this disruptive technology. […] And there is no excuse for failing to set clear rules so that it remains accountable, fosters our civic values and allows humanity to be stronger and better.”
The Lords Select Committee report on AI in the UK in March 2018, suggested that,“the Government plans to adopt the Hall-Pesenti Review recommendation that ‘data trusts’ be established to facilitate the ethical sharing of data between organisations.”
Since data distribution already happens, what difference would a Data Trust model make to ‘ethical sharing‘?
A ‘set of relationships underpinned by a repeatable framework, compliant with parties’ obligations’ seems little better than what we have today, with all its problems including deeply unethical policy and practice.
The ODI set out some of the characteristics Data Trusts might have or share. As importantly, we should define what Data Trusts are not. They should not simply be a new name for pooling content and a new single distribution point. Click and collect.
But is a Data Trust little more than a new description for what goes on already? Either a physical space or legal agreements for data users to pass around the personal data from the unsuspecting, and sometimes unwilling, public. Friends-with-benefits who each bring something to the party to share with the others?
As with any communal risk, it is the standards of the weakest link, the least ethical, the one that pees in the pool, that will increase reputational risk for all who take part, and spoil it for everyone.
Importantly, the Lords AI Committee report recognised that there is an inherent risk how the public would react to Data Trusts, because there is no social license for this new data sharing.
“Under the current proposals, individuals who have their personal data contained within these trusts would have no means by which they could make their views heard, or shape the decisions of these trusts.”
Views those keen on Data Trusts seem keen to ignore.
When the Administrative Data Research Network was set up in 2013, a new infrastructure for “deidentified” data linkage, extensive public dialogue was carried across across the UK. It concluded in a report with very similar findings as was apparent at dozens of care.data engagement events in 2014-15;
There is not public support for
“Creating large databases containing many variables/data from a large number of public sector sources,
Establishing greater permanency of datasets,
Allowing administrative data to be linked with business data, or
Linking of passively collected administrative data, in particular geo-location data”
The other ‘red-line’ for some participants was allowing “researchers for private companies to access data, either to deliver a public service or in order to make profit. Trust in private companies’ motivations were low.”
All of the above could be central to Data Trusts. All of the above highlight that in any new push to exploit personal data, the public must not be the last to know. And until all of the above are resolved, that social-license underpinning the work will always be missing.
Take the National Pupil Database (NPD) as a case study in a Data Trust done wrong.
It is a mega-database of over 20 other datasets. Raw data has been farmed out for years under terms and conditions to third parties, including users who hold an entire copy of the database, such as the somewhat secretive and unaccountable Fischer Family Trust, and others, who don’t answer to Freedom-of-Information, and whose terms are hidden under commercial confidentilaity. Buying and benchmarking data from schools and selling it back to some, profiling is hidden from parents and pupils, yet the FFT predictive risk scoring can shape a child’s school experience from age 2. They don’t really want to answer how staff tell if a child’s FFT profile and risk score predictions are accurate, or of they can spot errors or a wrong data input somewhere.
Even as the NPD moves towards risk reduction, its issues remain. When will children be told how data about them are used?
Is it any wonder that many people in the UK feel a resentment of institutions and orgs who feel entitled to exploit them, or nudge their behaviour, and a need to ‘take back control’?
It is naïve for those working in data policy and research to think that it does not apply to them.
We already have safe infrastructures in the UK for excellent data access. What users are missing, is the social license to do so.
No one should be talking about increasing access to public data, before delivering increased public understanding. Data users must get over their fear of what if the public found out.
If your data use being on the front pages would make you nervous, maybe it’s a clue you should be doing something differently. If you don’t trust the public would support it, then perhaps it doesn’t deserve to be trusted. Respect individuals’ dignity and human rights. Stop doing stupid things that undermine everything.
Build the social license that care.data was missing. Be honest. Respect our right to know, and right to object. Build them into a public UK data strategy to be understood and be proud of.
Part 1. Ethically problematic
Ethics is dissolving into little more than a buzzword. Can we find solutions underpinned by law, and ethics, and put the person first?
Part 2. Can Data Trusts be trustworthy? As long as data users ignore data subjects rights, Data Trusts have no social license.
What would it mean for you to trust an Internet connected product or service and why would you not?
What has damaged consumer trust in products and services and why do sellers care?
What do we want to see different from today, and what is necessary to bring about that change?
These three pairs of questions implicitly underpinned the intense day of #iotmark discussion at the London Zoo last Friday.
The questions went unasked, and could have been voiced before we started, although were probably assumed to be self-evident:
Why do you want one at all [define the problem]?
What needs to change and why [define the future model]?
How do you deliver that and for whom [set out the solution]?
If a group does not agree on the need and drivers for change, there will be no consensus on what that should look like, what the gap is to achieve it, and even less on making it happen.
So who do you want the trustmark to be for, why will anyone want it, and what will need to change to deliver the aims? No one wants a trustmark per se. Perhaps you want what values or promises it embodies to demonstrate what you stand for, promote good practice, and generate consumer trust. To generate trust, you must be seen to be trustworthy. Will the principles deliver on those goals?
The Open IoT Certification Mark Principles, as a rough draft was the outcome of the day, and are available online.
Here’s my reflections, including what was missing on privacy, and the potential for it to be considered in future.
I’ve structured this first, assuming readers attended the event, at ca 1,000 words. Lists and bullet points. The background comes after that, for anyone interested to read a longer piece.
Many thanks upfront, to fellow participants, to the organisers Alexandra D-S and Usman Haque and the colleague who hosted at the London Zoo. And Usman’s Mum. I hope there will be more constructive work to follow, and that there is space for civil society to play a supporting role and critical friend.
The mark didn’t aim to fix the IoT in a day, but deliver something better for product and service users, by those IoT companies and providers who want to sign up. Here is what I took away.
I learned three things
A sense of privacy is not homogenous, even within people who like and care about privacy in theoretical and applied ways. (I very much look forward to reading suggestions promised by fellow participants, even if enforced personal openness and ‘watching the watchers’ may mean ‘privacy is theft‘.)
Awareness of current data protection regulations needs improved in the field. For example, Subject Access Requests already apply to all data controllers, public and private. Few have read the GDPR, or the e-Privacy directive, despite importance for security measures in personal devices, relevant for IoT.
I truly love working on this stuff, with people who care.
And it reaffirmed things I already knew
Change is hard, no matter in what field.
People working together towards a common goal is brilliant.
Group collaboration can create some brilliantly sharp ideas. Group compromise can blunt them.
Some men are particularly bad at talking over each other, never mind over the women in the conversation. Women notice more. (Note to self: When discussion is passionate, it’s hard to hold back in my own enthusiasm and not do the same myself. To fix.)
The IoT context, and risks within it are not homogenous, but brings new risks and adverseries. The risks for manufacturers and consumers and the rest of the public are different, and cannot be easily solved with a one-size-fits-all solution. But we can try.
Concerns I came away with
If the citizen / customer / individual is to benefit from the IoT trustmark, they must be put first, ahead of companies’ wants.
If the IoT group controls both the design, assessment to adherence and the definition of success, how objective will it be?
The group was not sufficiently diverse and as a result, reflects too little on the risks and impact of the lack of diversity in design and effect, and the implications of dataveillance .
Critical minority thoughts although welcomed, were stripped out from crowdsourced first draft principles in compromise.
More future thinking should be built-in to be robust over time.
What was missing
There was too little discussion of privacy in perhaps the most important context of IoT – inter connectivity and new adversaries. It’s not only about *your* thing, but things that it speaks to, interacts with, of friends, passersby, the cityscape , and other individual and state actors interested in offense and defense. While we started to discuss it, we did not have the opportunity to discuss sufficiently at depth to be able to get any thinking into applying solutions in the principles.
One of the greatest risks that users face is the ubiquitous collection and storage of data about users that reveal detailed, inter-connected patterns of behaviour and our identity and not seeing how that is used by companies behind the scenes.
What we also missed discussing is not what we see as necessary today, but what we can foresee as necessary for the short term future, brainstorming and crowdsourcing horizon scanning for market needs and changing stakeholder wants.
Future thinking
Here’s the areas of future thinking that smart thinking on the IoT mark could consider.
We are moving towards ever greater requirements to declare identity to use a product or service, to register and log in to use anything at all. How will that change trust in IoT devices?
Single identity sign-on is becoming ever more imposed, and any attempts for multiple presentation of who I am by choice, and dependent on context, therefore restricted. [not all users want to use the same social media credentials for online shopping, with their child’s school app, and their weekend entertainment]
Is this imposition what the public wants or what companies sell us as what customers want in the name of convenience? What I believe the public would really want is the choice to do neither.
There is increasingly no private space or time, at places of work.
Limitations on private space are encroaching in secret in all public city spaces. How will ‘handoffs’ affect privacy in the IoT?
There is too little understanding of the social effects of this connectedness and knowledge created, embedded in design.
What effects may there be on the perception of the IoT as a whole, if predictive data analysis and complex machine learning and AI hidden in black boxes becomes more commonplace and not every company wants to be or can be open-by-design?
Ubiquitous collection and storage of data about users that reveal detailed, inter-connected patterns of behaviour and our identity needs greater commitments to disclosure. Where the hand-offs are to other devices, and whatever else is in the surrounding ecosystem, who has responsibility for communicating interaction through privacy notices, or defining legitimate interests, where the data joined up may be much more revealing than stand-alone data in each silo?
Define with greater clarity the privacy threat models for different groups of stakeholders and address the principles for each.
What would better look like?
The draft privacy principles are a start, but they’re not yet aspirational as I would have hoped. Of course the principles will only be adopted if possible, practical and by those who choose to. But where is the differentiator from what everyone is required to do, and better than the bare minimum? How will you sell this to consumers as new? How would you like your child to be treated?
The wording in these 5 bullet points, is the first crowdsourced starting point.
The supplier of this product or service MUST be General Data Protection Regulation (GDPR) compliant.
This product SHALL NOT disclose data to third parties without my knowledge.
I SHOULD get full access to all the data collected about me.
I MAY operate this device without connecting to the internet.
My data SHALL NOT be used for profiling, marketing or advertising without transparent disclosure.
Yes other points that came under security address some of the crossover between privacy and surveillance risks, but there is as yet little substantial that is aspirational to make the IoT mark a real differentiator in terms of privacy. An opportunity remains.
It was that and how young people perceive privacy that I hoped to bring to the table. Because if manufacturers are serious about future success, they cannot ignore today’s children and how they feel. How you treat them today, will shape future purchasers and their purchasing, and there is evidence you are getting it wrong.
The timing is good in that it now also offers the opportunity to promote consistent understanding, and embed the language of GDPR and ePrivacy regulations into consistent and compatible language in policy and practice in the #IoTmark principles.
User rights I would like to see considered
These are some of the points I would think privacy by design would mean. This would better articulate GDPR Article 25 to consumers.
Data sovereignty is a good concept and I believe should be considered for inclusion in explanatory blurb before any agreed privacy principles.
Goods should by ‘dumb* by default’ until the smart functionality is switched on. [*As our group chair/scribe called it] I would describe this as, “off is the default setting out-of-the-box”.
Privact by design. Deniability by default. i.e. not only after opt out, but a company should not access the personal or identifying purchase data of anyone who opts out of data collection about their product/service use during the set up process.
The right to opt out of data collection at a later date while continuing to use services.
A right to object to the sale or transfer of behavioural data, including to third-party ad networks and absolute opt-in on company transfer of ownership.
A requirement that advertising should be targeted to content, [user bought fridge A] not through jigsaw data held on users by the company [how user uses fridge A, B, C and related behaviour].
An absolute rejection of using children’s personal data gathered to target advertising and marketing at children
Background: Starting points before privacy
After a brief recap on 5 years ago, we heard two talks.
The first was a presentation from Bosch. They used the insights from the IoT open definition from 5 years ago in their IoT thinking and embedded it in their brand book. The presenter suggested that in five years time, every fridge Bosch sells will be ‘smart’. And the second was a fascinating presentation, of both EU thinking and the intellectual nudge to think beyond the practical and think what kind of society we want to see using the IoT in future. Hints of hardcore ethics and philosophy that made my brain fizz from Gerald Santucci, soon to retire from the European Commission.
The principles of open sourcing, manufacturing, and sustainable life cycle were debated in the afternoon with intense arguments and clearly knowledgeable participants, including those who were quiet. But while the group had assigned security, and started work on it weeks before, there was no one pre-assigned to privacy. For me, that said something. If they are serious about those who earn the trustmark being better for customers than their competition, then there needs to be greater emphasis on thinking like their customers, and by their customers, and what use the mark will be to customers, not companies. Plan early public engagement and testing into the design of this IoT mark, and make that testing open and diverse.
To that end, I believe it needed to be articulated more strongly, that sustainable public trust is the primary goal of the principles.
Trust that my device will not become unusable or worthless through updates or lack of them.
Trust that my device is manufactured safely and ethically and with thought given to end of life and the environment.
Trust that my source components are of high standards.
Trust in what data and how that data is gathered and used by the manufacturers.
Fundamental to ‘smart’ devices is their connection to the Internet, and so the last for me, is therefore key to successful public perception and it actually making a difference, beyond the PR value to companies. The value-add must be measured from consumers point of view.
All the openness about design functions and practice improvements, without attempting to change privacy infringing practices, may be wasted effort. Why? Because the perceived benefit of the value of the mark, will be proportionate to what risks it is seen to mitigate.
Why?
Because I assume that you know where your source components come from today. I was shocked to find out not all do and that ‘one degree removed’ is going to be an improvement? Holy cow, I thought. What about regulatory requirements for product safety recalls? These differ of course for different product areas, but I was still surprised. Having worked in global Fast Moving Consumer Goods (FMCG) and food industry, semiconductor and optoelectronics, and medical devices it was self-evident for me, that sourcing is rigorous. So that new requirement to know one degree removed, was a suggested minimum. But it might shock consumers to know there is not usually more by default.
Customers also believe they have reasonable expectations of not being screwed by a product update, left with something that does not work because of its computing based components. The public can take vocal, reputation-damaging action when they are let down.
While these are visible, the full extent of the overreach of company market and product surveillance into our whole lives, not just our living rooms, is yet to become understood by the general population. What will happen when it is?
The Internet of Things is exacerbating the power imbalance between consumers and companies, between government and citizens. As Wendy Grossman wrote recently, in one sense this may make privacy advocates’ jobs easier. It was always hard to explain why “privacy” mattered. Power, people understand.
That public discussion is long overdue. If open principles on IoT devices mean that the signed-up companies differentiate themselves by becoming market leaders in transparency, it will be a great thing. Companies need to offer full disclosure of data use in any privacy notices in clear, plain language under GDPR anyway, but to go beyond that, and offer customers fair presentation of both risks and customer benefits, will not only be a point-of-sales benefit, but potentially improve digital literacy in customers too.
The morning discussion touched quite often on pay-for-privacy models. While product makers may see this as offering a good thing, I strove to bring discussion back to first principles.
Privacy is a human right. There can be no ethical model of discrimination based on any non-consensual invasion of privacy. Privacy is not something I should pay to have. You should not design products that reduce my rights. GDPR requires privacy-by-design and data protection by default. Now is that chance for IoT manufacturers to lead that shift towards higher standards.
We also need a new ethics thinking on acceptable fair use. It won’t change overnight, and perfect may be the enemy of better. But it’s not a battle that companies should think consumers have lost. Human rights and information security should not be on the battlefield at all in the war to win customer loyalty. Now is the time to do better, to be better, demand better for us and in particular, for our children.
Privacy will be a genuine market differentiator
If manufacturers do not want to change their approach to exploiting customer data, they are unlikely to be seen to have changed.
Today feelings that people in US and Europe reflect in surveys are loss of empowerment, feeling helpless, and feeling used. That will shift to shock, resentment, and any change curve will predict, anger.
“The poll of just over two thousand British adults carried out by Ipsos MORI found that the media, internet services such as social media and search engines and telecommunication companies were the least trusted to use personal data appropriately.” [2014, Data trust deficit with lessons for policymakers, Royal Statistical Society]
In the British student population, one 2015 survey of university applicants in England, found of 37,000 who responded, the vast majority of UCAS applicants agree that sharing personal data can benefit them and support public benefit research into university admissions, but they want to stay firmly in control. 90% of respondents said they wanted to be asked for their consent before their personal data is provided outside of the admissions service.
In 2010, a multi method model of research with young people aged 14-18, by the Royal Society of Engineering, found that, “despite their openness to social networking, the Facebook generation have real concerns about the privacy of their medical records.” [2010, Privacy and Prejudice, RAE, Wellcome]
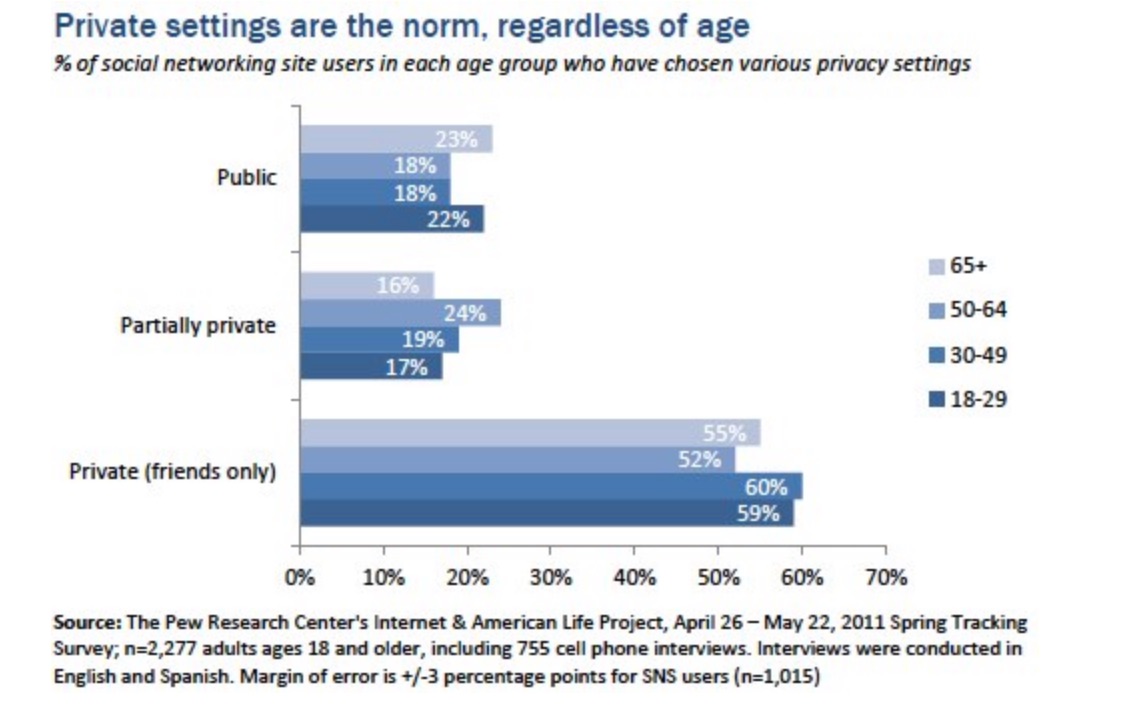
When people use privacy settings on Facebook set to maximum, they believe they get privacy, and understand little of what that means behind the scenes.
Are there tools designed by others, like Projects by If licenses, and ways this can be done, that you’re not even considering yet?
What if you don’t do it?
“But do you feel like you have privacy today?” I was asked the question in the afternoon. How do people feel today, and does it matter? Companies exploiting consumer data and getting caught doing things the public don’t expect with their data, has repeatedly damaged consumer trust. Data breaches and lack of information security have damaged consumer trust. Both cause reputational harm. Damage to reputation can harm customer loyalty. Damage to customer loyalty costs sales, profit and upsets the Board.
Where overreach into our living rooms has raised awareness of invasive data collection, we are yet to be able to see and understand the invasion of privacy into our thinking and nudge behaviour, into our perception of the world on social media, the effects on decision making that data analytics is enabling as data shows companies ‘how we think’, granting companies access to human minds in the abstract, even before Facebook is there in the flesh.
Governments want to see how we think too, and is thought crime really that far away using database labels of ‘domestic extremists’ for activists and anti-fracking campaigners, or the growing weight of policy makers attention given to predpol, predictive analytics, the [formerly] Cabinet Office Nudge Unit, Google DeepMind et al?
Had the internet remained decentralized the debate may be different.
I am starting to think of the IoT not as the Internet of Things, but as the Internet of Tracking. If some have their way, it will be the Internet of Thinking.
Considering our centralised Internet of Things model, our personal data from human interactions has become the network infrastructure, and data flows, are controlled by others. Our brains are the new data servers.
In the Internet of Tracking, people become the end nodes, not things.
And it is this where the future users will be so important. Do you understand and plan for factors that will drive push back, and crash of consumer confidence in your products, and take it seriously?
Companies have a choice to act as Empires would – multinationals, joining up even on low levels, disempowering individuals and sucking knowledge and power at the centre. Or they can act as Nation states ensuring citizens keep their sovereignty and control over a selected sense of self.
Look at Brexit. Look at the GE2017. Tell me, what do you see is the direction of travel? Companies can fight it, but will not defeat how people feel. No matter how much they hope ‘nudge’ and predictive analytics might give them this power, the people can take back control.
What might this desire to take-back-control mean for future consumer models? The afternoon discussion whilst intense, reached fairly simplistic concluding statements on privacy. We could have done with at least another hour.
Some in the group were frustrated “we seem to be going backwards” in current approaches to privacy and with GDPR.
But if the current legislation is reactive because companies have misbehaved, how will that be rectified for future? The challenge in the IoT both in terms of security and privacy, AND in terms of public perception and reputation management, is that you are dependent on the behaviours of the network, and those around you. Good and bad. And bad practices by one, can endanger others, in all senses.
If you believe that is going back to reclaim a growing sense of citizens’ rights, rather than accepting companies have the outsourced power to control the rights of others, that may be true.
There was a first principle asked whether any element on privacy was needed at all, if the text was simply to state, that the supplier of this product or service must be General Data Protection Regulation (GDPR) compliant. The GDPR was years in the making after all. Does it matter more in the IoT and in what ways? The room tended, understandably, to talk about it from the company perspective. “We can’t” “won’t” “that would stop us from XYZ.” Privacy would however be better addressed from the personal point of view.
What do people want?
From the company point of view, the language is different and holds clues. Openness, control, and user choice and pay for privacy are not the same thing as the basic human right to be left alone. Afternoon discussion reminded me of the 2014 WAPO article, discussing Mark Zuckerberg’s theory of privacy and a Palo Alto meeting at Facebook:
“Not one person ever uttered the word “privacy” in their responses to us. Instead, they talked about “user control” or “user options” or promoted the “openness of the platform.” It was as if a memo had been circulated that morning instructing them never to use the word “privacy.””
In the afternoon working group on privacy, there was robust discussion whether we had consensus on what privacy even means. Words like autonomy, control, and choice came up a lot. But it was only a beginning. There is opportunity for better. An academic voice raised the concept of sovereignty with which I agreed, but how and where to fit it into wording, which is at once both minimal and applied, and under a scribe who appeared frustrated and wanted a completely different approach from what he heard across the group, meant it was left out.
This group do care about privacy. But I wasn’t convinced that the room cared in the way that the public as a whole does, but rather only as consumers and customers do. But IoT products will affect potentially everyone, even those who do not buy your stuff. Everyone in that room, agreed on one thing. The status quo is not good enough. What we did not agree on, was why, and what was the minimum change needed to make a enough of a difference that matters.
I share the deep concerns of many child rights academics who see the harm that efforts to avoid restrictions Article 8 the GDPR will impose. It is likely to be damaging for children’s right to access information, be discriminatory according to parents’ prejudices or socio-economic status, and ‘cheating’ – requiring secrecy rather than privacy, in attempts to hide or work round the stringent system.
In ‘The Class’ the research showed, ” teachers and young people have a lot invested in keeping their spheres of interest and identity separate, under their autonomous control, and away from the scrutiny of each other.” [2016, Livingstone and Sefton-Green, p235]
Employers require staff use devices with single sign including web and activity tracking and monitoring software. Employee personal data and employment data are blended. Who owns that data, what rights will employees have to refuse what they see as excessive, and is it manageable given the power imbalance between employer and employee?
What is this doing in the classroom and boardroom for stress, anxiety, performance and system and social avoidance strategies?
A desire for convenience creates shortcuts, and these are often met using systems that require a sign-on through the platforms giants: Google, Facebook, Twitter, et al. But we are kept in the dark how by using these platforms, that gives access to them, and the companies, to see how our online and offline activity is all joined up.
Any illusion of privacy we maintain, we discussed, is not choice or control if based on ignorance, and backlash against companies lack of efforts to ensure disclosure and understanding is growing.
“The lack of accountability isn’t just troubling from a philosophical perspective. It’s dangerous in a political climate where people are pushing back at the very idea of globalization. There’s no industry more globalized than tech, and no industry more vulnerable to a potential backlash.”
If your connected *thing* requires registration, why does it? How about a commitment to not forcing one of these registration methods or indeed any at all? Social Media Research by Pew Research in 2016 found that 56% of smartphone owners ages 18 to 29 use auto-delete apps, more than four times the share among those 30-49 (13%) and six times the share among those 50 or older (9%).
Does that tell us anything about the demographics of data retention preferences?
In 2012, they suggested social media has changed the public discussion about managing “privacy” online. When asked, people say that privacy is important to them; when observed, people’s actions seem to suggest otherwise.
Does that tell us anything about how well companies communicate to consumers how their data is used and what rights they have?
There is also data with strong indications about how women act to protect their privacy more but when it comes to basic privacy settings, users of all ages are equally likely to choose a private, semi-private or public setting for their profile. There are no significant variations across age groups in the US sample.
Now think about why that matters for the IoT? I wonder who makes the bulk of purchasing decsions about household white goods for example and has Bosch factored that into their smart-fridges-only decision?
Do you *need* to know who the user is? Can the smart user choose to stay anonymous at all?
The day’s morning challenge was to attend more than one interesting discussion happening at the same time. As invariably happens, the session notes and quotes are always out of context and can’t possibly capture everything, no matter how amazing the volunteer (with thanks!). But here are some of the discussion points from the session on the body and health devices, the home, and privacy. It also included a discussion on racial discrimination, algorithmic bias, and the reasons why care.data failed patients and failed as a programme. We had lengthy discussion on ethics and privacy: smart meters, objections to models of price discrimination, and why pay-for-privacy harms the poor by design.
Smart meter data can track the use of unique appliances inside a person’s home and intimate patterns of behaviour. Information about our consumption of power, what and when every day, reveals personal details about everyday lives, our interactions with others, and personal habits.
Why should company convenience come above the consumer’s? Why should government powers, trump personal rights?
Smart meter is among the knowledge that government is exploiting, without consent, to discover a whole range of issues, including ensuring that “Troubled Families are identified”. Knowing how dodgy some of the school behaviour data might be, that helps define who is “troubled” there is a real question here, is this sound data science? How are errors identified? What about privacy? It’s not your policy, but if it is your product, what are your responsibilities?
If companies do not respect children’s rights, you’d better shape up to be GDPR compliant
For children and young people, more vulnerable to nudge, and while developing their sense of self can involve forming, and questioning their identity, these influences need oversight or be avoided.
In terms of GDPR, providers are going to pay particular attention to Article 8 ‘information society services’ and parental consent, Article 17 on profiling, and rights to restriction of processing (19) right to erasure in recital 65 and rights to portability. (20) However, they may need to simply reassess their exploitation of children and young people’s personal data and behavioural data. Article 57 requires special attention to be paid by regulators to activities specifically targeted at children, as ‘vulnerable natural persons’ of recital 75.
Human Rights, regulations and conventions overlap in similar principles that demand respect for a child, and right to be let alone:
(a) The development of the child ‘s personality, talents and mental and physical abilities to their fullest potential;
(b) The development of respect for human rights and fundamental freedoms, and for the principles enshrined in the Charter of the United Nations.
A weakness of the GDPR is that it allows derogation on age and will create inequality and inconsistency for children as a result. By comparison Article one of the Convention on the Rights of the Child (CRC) defines who is to be considered a “child” for the purposes of the CRC, and states that: “For the purposes of the present Convention, a child means every human being below the age of eighteen years unless, under the law applicable to the child, majority is attained earlier.”<
Article two of the CRC says that States Parties shall respect and ensure the rights set forth in the present Convention to each child within their jurisdiction without discrimination of any kind.
CRC Article 16 says that no child shall be subjected to arbitrary or unlawful interference with his or her honour and reputation.
Article 8 CRC requires respect for the right of the child to preserve his or her identity […] without unlawful interference.
Article 12 CRC demands States Parties shall assure to the child who is capable of forming his or her own views the right to express those views freely in all matters affecting the child, the views of the child being given due weight in accordance with the age and maturity of the child.
That stands in potential conflict with GDPR article 8. There is much on GDPR on derogations by country, and or children, still to be set.
What next for our data in the wild
Hosting the event at the zoo offered added animals, and during a lunch tour we got out on a tour, kindly hosted by a fellow participant. We learned how smart technology was embedded in some of the animal enclosures, and work on temperature sensors with penguins for example. I love tigers, so it was a bonus that we got to see such beautiful and powerful animals up close, if a little sad for their circumstances and as a general basic principle, seeing big animals caged as opposed to in-the-wild.
Freedom is a common desire in all animals. Physical, mental, and freedom from control by others.
I think any manufacturer that underestimates this element of human instinct is ignoring the ‘hidden dragon’ that some think is a myth. Privacy is not dead. It is not extinct, or even unlike the beautiful tigers, endangered. Privacy in the IoT at its most basic, is the right to control our purchasing power. The ultimate people power waiting to be sprung. Truly a crouching tiger. People object to being used and if companies continue to do so without full disclosure, they do so at their peril. Companies seem all-powerful in the battle for privacy, but they are not. Even insurers and data brokers must be fair and lawful, and it is for regulators to ensure that practices meet the law.
When consumers realise our data, our purchasing power has the potential to control, not be controlled, that balance will shift.
“Paper tigers” are superficially powerful but are prone to overextension that leads to sudden collapse. If that happens to the superficially powerful companies that choose unethical and bad practice, as a result of better data privacy and data ethics, then bring it on.
I hope that the IoT mark can champion best practices and make a difference to benefit everyone.
While the companies involved in its design may be interested in consumers, I believe it could be better for everyone, done well. The great thing about the efforts into an #IoTmark is that it is a collective effort to improve the whole ecosystem.
I hope more companies will realise their privacy rights and ethical responsibility in the world to all people, including those interested in just being, those who want to be let alone, and not just those buying.
“If a cat is called a tiger it can easily be dismissed as a paper tiger; the question remains however why one was so scared of the cat in the first place.”
Further reading: Networks of Control – A Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy by Wolfie Christl and Sarah Spiekermann
In preparation for The General Data Protection Regulation (GDPR) there must be an active UK decision about policy in the coming months for children and the Internet – provision of ‘Information Society Services’. The age of consent for online content aimed at children from May 25, 2018 will be 16 by default unless UK law is made to lower it.
Age verification for online information services in the GDPR, will mean capturing parent-child relationships. This could mean a parent’s email or credit card unless there are other choices made. What will that mean for access to services for children and to privacy? It is likely to offer companies an opportunity for a data grab, and mean privacy loss for the public, as more data about family relationships will be created and collected than the content provider would get otherwise.
Our interactions create a blended identity of online and offline attributes which I suggested in a previous post, create synthesised versions of our selves raises questions on data privacy and security.
The goal may be to protect the physical child. The outcome will mean it simultaneously expose children and parents to risks that we would not otherwise be put through increased personal data collection. By increasing the data collected, it increases the associated risks of loss, theft, and harm to identity integrity. How will legislation balance these risks and rights to participation?
The UK government has various work in progress before then, that could address these questions:
As Sonia Livingstone wrote in the post on the LSE media blog about what to expect from the GDPR and its online challenges for children:
“Now the UK, along with other Member States, has until May 2018 to get its house in order”.
What will that order look like?
The Digital Strategy and Ed Tech
The Digital Strategy commits to changes in National Pupil Data management. That is, changes in the handling and secondary uses of data collected from pupils in the school census, like using it for national research and planning.
Access to NPD via the ONS VML would mean safe data use, in safe settings, by safe (trained and accredited) users.
Sensitive data — it remains to be seen how DfE intends to interpret ‘sensitive’ and whether that is the DPA1998 term or lay term meaning ‘identifying’ as it should — will no longer be seen by users for secondary uses outside safe settings.
However, a grey area on privacy and security remains in the “Data Exchange” which will enable EdTech products to “talk to each other”.
The aim of changes in data access is to ensure that children’s data integrity and identity are secure. Let’s hope the intention that “at all times, the need to preserve appropriate privacy and security will remain paramount and will be non-negotiable” applies across all closed pupil data, and not only to that which may be made available via the VML.
This strategy is still far from clear or set in place.
The Digital Strategy and consumer data rights
The Digital Strategy commits under the heading of “Unlocking the power of data in the UK economy and improving public confidence in its use” to the implementation of the General Data Protection Regulation by May 2018. The Strategy frames this as a business issue, labelling data as “a global commodity” and as such, its handling is framed solely as a requirements needed to ensure “that our businesses can continue to compete and communicate effectively around the world” and that adoption “will ensure a shared and higher standard of protection for consumers and their data.”
The GDPR as far as children goes, is far more about protection of children as people. It focuses on returning control over children’s own identity and being able to revoke control by others, rather than consumer rights.
That said, there are data rights issues which are also consumer issues and product safety failures posing real risk of harm.
Neither The Digital Economy Bill nor the Digital Strategy address these rights and security issues, particularly when posed by the Internet of Things with any meaningful effect.
In fact, the chapter Internet of Things and Smart Infrastructure [ 9/19] singularly miss out anything on security and safety:
“We want the UK to remain an international leader in R&D and adoption of IoT. We are funding research and innovation through the three year, £30 million IoT UK Programme.”
If it’s not scary enough for the public to think that their sex secrets and devices are hackable, perhaps it will kill public trust in connected devices more when they find strangers talking to their children through a baby monitor or toy. [BEUC campaign report on #Toyfail]
“The internet-connected toys ‘My Friend Cayla’ and ‘i-Que’ fail miserably when it comes to safeguarding basic consumer rights, security, and privacy. Both toys are sold widely in the EU.”
Digital skills and training in the strategy doesn’t touch on any form of change management plans for existing working sectors in which we expect to see machine learning and AI change the job market. This is something the digital and industrial strategy must be addressing hand in glove.
The tactics and training providers listed sound super, but there does not appear to be an aspirational strategy hidden between the lines.
The Digital Economy Bill and citizens’ data rights
While the rest of Europe in this legislation has recognised that a future thinking digital world without boundaries, needs future thinking on data protection and empowered citizens with better control of identity, the UK government appears intent on taking ours away.
To take only one example for children, the Digital Economy Bill in Cabinet Office led meetings was explicit about use for identifying and tracking individuals labelled under “Troubled Families” and interventions with them. Why, when consent is required to work directly with people, that consent is being ignored to access their information is baffling and in conflict with both the spirit and letter of GDPR. Students and Applicants will see their personal data sent to the Student Loans Company without their consent or knowledge. This overrides the current consent model in place at UCAS.
It is baffling that the government is pursuing the Digital Economy Bill data copying clauses relentlessly, that remove confidentiality by default, and will release our identities in birth, marriage and death data for third party use without consent through Chapter 2, the opening of the Civil Registry, without any safeguards in the bill.
Government has not only excluded important aspects of Parliamentary scrutiny in the bill, it is trying to introduce “almost untrammeled powers” (paragraph 21), that will “very significantly broaden the scope for the sharing of information” and “specified persons” which applies “whether the service provider concerned is in the public sector or is a charity or a commercial organisation” and non-specific purposes for which the information may be disclosed or used. [Reference: Scrutiny committee comments]
Future changes need future joined up thinking
While it is important to learn from the past, I worry that the effort some social scientists put into looking backwards, is not matched by enthusiasm to look ahead and making active recommendations for a better future.
Society appears to have its eyes wide shut to the risks of coercive control and nudge as research among academics and government departments moves in the direction of predictive data analysis.
Uses of administrative big data and publicly available social media data for example, in research and statistics, needs further new regulation in practice and policy but instead the Digital Economy Bill looks only at how more data can be got out of Department silos.
A certain intransigence about data sharing with researchers from government departments is understandable. What’s the incentive for DWP to release data showing its policy may kill people?
Westminster may fear it has more to lose from data releases and don’t seek out the political capital to be had from good news.
The ethics of data science are applied patchily at best in government, and inconsistently in academic expectations.
Some researchers have identified this but there seems little will to action:
“It will no longer be possible to assume that secondary data use is ethically unproblematic.”
Research and legislation alike seem hell bent on the low hanging fruit but miss out the really hard things. What meaningful benefit will it bring by spending millions of pounds on exploiting these personal data and opening our identities to risk just to find out whether X course means people are employed in Y tax bracket 5 years later, versus course Z where everyone ends up self employed artists? What ethics will be applied to the outcomes of those questions asked and why?
And while government is busy joining up children’s education data throughout their lifetimes from age 2 across school, FE, HE, into their HMRC and DWP interactions, there is no public plan in the Digital Strategy for the coming 10 to 20 years employment market, when many believe, as do these authors in American Scientific, “around half of today’s jobs will be threatened by algorithms. 40% of today’s top 500 companies will have vanished in a decade.”
What benefit will it have to know what was, or for the plans around workforce and digital skills list ad hoc tactics, but no strategy?
We must safeguard jobs and societal needs, but just teaching people to code is not a solution to a fundamental gap in what our purpose will be, and the place of people as a world-leading tech nation after Brexit. We are going to have fewer talented people from across the world staying on after completing academic studies, because they’re not coming at all.
There may be investment in A.I. but where is the investment in good data practices around automation and machine learning in the Digital Economy Bill?
To do this Digital Strategy well, we need joined up thinking.
Children should be able to use online services without being used and abused by them.
This article arrived on my Twitter timeline via a number of people. Doteveryone CEO Rachel Coldicutt summed up various strands of thought I started to hear hints of last month at #CPDP2017 in Brussels:
“As designers and engineers, we’ve contributed to a post-thought world. In 2017, it’s time to start making people think again.
“We need to find new ways of putting friction and thoughtfulness back into the products we make.” [Glanceable truthiness, 30.1.2017]
Let’s keep the human in discussions about technology, and people first in our products
All too often in technology and even privacy discussions, people have become ‘consumers’ and ‘customers’ instead of people.
The Digital Strategy may seek to unlock “the power of data in the UK economy” but policy and legislation must put equal if not more emphasis on “improving public confidence in its use” if that long term opportunity is to be achieved.
And in technology discussions about AI and algorithms we hear very little about people at all. Discussions I hear seem siloed instead into three camps: the academics, the designers and developers, the politicians and policy makers. And then comes the lowest circle, ‘the public’ and ‘society’.
It is therefore unsurprising that human rights have fallen down the ranking of importance in some areas of technology development.